Le service d'enrichissement était down pendant 20 minutes. Pas grave--les services tombent. Mais quand il est revenu, j'avais 50 000 items coincés dans une queue, et notre index de recherche n'avait pas été mis à jour depuis une demi-heure.
Les utilisateurs cherchaient des produits qu'on avait ajoutés le matin même. Rien n'apparaissait. Les produits existaient dans notre système, mais ils attendaient en ligne derrière un backlog d'items qui avaient besoin d'"enrichissement" avant de pouvoir être indexés.
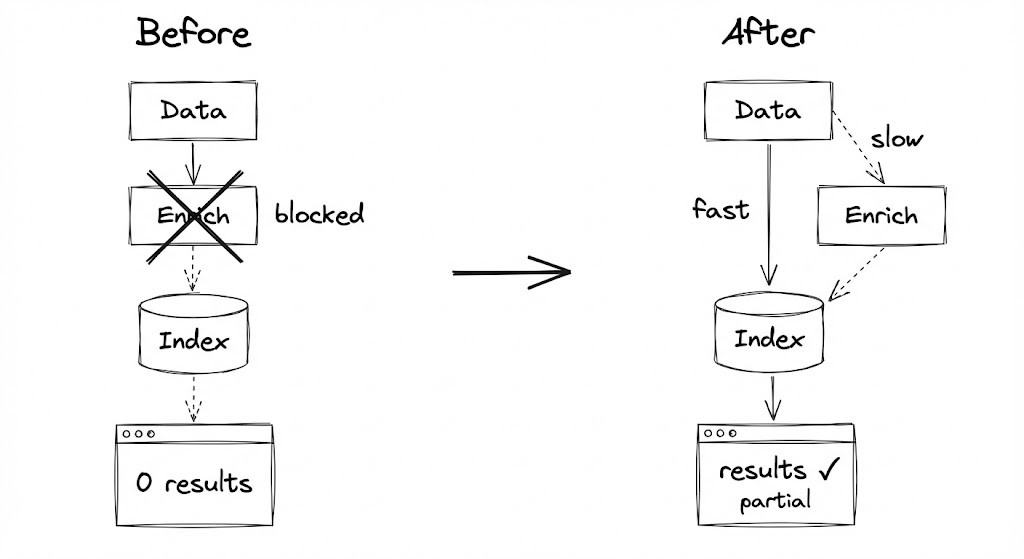
C'est là que j'ai réalisé que j'avais construit un pipeline avec un seul point d'étranglement. Et chaque fois que la partie lente ralentissait, la partie rapide s'arrêtait complètement.
Comment je me suis mis dans ce pétrin
L'architecture originale était simple et sensée. Quand un nouveau produit arrivait :
- Récupérer les données de base (nom, prix, URL de l'image)
- Appeler le service d'enrichissement (obtenir descriptions, extraire mots-clés, lancer classification)
- Indexer le record complet
Un pipeline. Un flow. Facile à raisonner.
Le problème était l'étape 2. Le service d'enrichissement appelait des APIs externes. Parfois ces APIs étaient lentes. Parfois elles nous limitaient. Parfois elles ne répondaient tout simplement pas.
Quand l'étape 2 prenait 500ms au lieu de 50ms, pas grave. Quand ça prenait 5 secondes, on commençait à prendre du retard. Quand le service tombait complètement, tout s'arrêtait.
J'ai essayé les fixes évidents. Logique de retry. Timeouts. Parallélisation. Ils aidaient à la marge, mais ne résolvaient pas le problème fondamental : je bloquais les opérations rapides sur les lentes.
La question qui a tout changé
J'expliquais le problème à un collègue, et elle a demandé : "Pourquoi as-tu besoin d'enrichissement avant indexation ? Les utilisateurs ne peuvent-ils pas chercher le produit par nom pendant que tu récupères encore la description ?"
J'ai commencé à expliquer pourquoi ça ne marcherait pas... et puis je me suis arrêté. Parce qu'en fait, ça marcherait. La plupart de nos recherches matchaient sur le nom et la marque du produit. Les données d'enrichissement rendaient les résultats meilleurs, mais leur absence ne les rendait pas impossibles.
Le shift mental : je traitais "complet" comme un prérequis pour "trouvable." Mais trouvable-avec-gaps est mieux que pas-trouvable-du-tout.
Deux pipelines, pas un
Voici ce que j'ai construit à la place :
PHASE 1: INITIALIZE (Fast Path)
+-------------------------------------------------------------+
| Données arrivent -> Validation basique -> Index immédiatement|
| |
| Latence : < 1 seconde |
| Complétude : ~50% des champs |
| Priorité : RENDRE TROUVABLE MAINTENANT |
+-------------------------------------------------------------+
|
v
[Queue d'Enrichissement]
|
v
PHASE 2: ENRICH (Slow Path)
+-------------------------------------------------------------+
| Dequeue -> Fetch details -> Merge avec existant -> Update |
| |
| Latence : minutes (acceptable) |
| Complétude : 100% des champs |
| Priorité : RENDRE COMPLET ÉVENTUELLEMENT |
+-------------------------------------------------------------+
L'insight clé : Phase 1 n'attend jamais Phase 2. Elles sont complètement découplées. Si le service d'enrichissement tombe, les items sont quand même indexés. Ils sont juste... incomplets. Pour l'instant.
"Des données incomplètes qui sont cherchables valent mieux que des données complètes qui sont invisibles."
La partie plus compliquée que prévu
La logique de merge. Quand les données d'enrichissement arrivent, tu ne peux pas juste écraser le record existant. Pourquoi pas ?
Parce que pendant que l'item attendait dans la queue d'enrichissement, le fast path pourrait l'avoir mis à jour. Peut-être que le prix a changé. Peut-être que la disponibilité a changé. Si tu écrases aveuglément avec les données d'enrichissement, tu pourrais clobber des informations plus fraîches.
J'ai fini par définir des règles explicites pour chaque type de champ. La fonction de merge vérifie le type de chaque champ et applique la bonne règle. C'est plus de code que je voulais, mais c'est explicite sur ce qui gagne quand.
Ce qui m'a eu en production
Les utilisateurs ont remarqué les records incomplets. Ils cherchaient, trouvaient quelque chose, cliquaient, et voyaient une description vide. Certains se sont plaints. J'ai ajouté un indicateur visuel--un message subtil "chargement des détails..."--et les plaintes ont cessé. Être honnête sur l'incomplétude était mieux que de prétendre qu'elle n'existait pas.
La queue d'enrichissement a grandi sans limite. Pendant une panne particulièrement mauvaise, je suis revenu à 200 000 items en attente d'enrichissement. La queue mangeait la mémoire. J'ai ajouté du backpressure : si la queue dépasse un seuil, pause l'ingestion ou drop les items de basse priorité. Ça semblait mal de drop du travail, mais c'était mieux que de crasher.
La priorité compte. Tous les enrichissements ne sont pas égaux. Un produit que quelqu'un vient de chercher devrait sauter devant un produit ajouté il y a six mois. J'ai ajouté des niveaux de priorité avec des conditions pour items critiques, haute, normale et basse priorité.
Le staleness s'installe. Les données d'enrichissement peuvent aussi devenir stale. Cette description d'il y a six mois pourrait référencer une fonctionnalité que le produit n'a plus. J'ai ajouté un job en arrière-plan qui re-queue périodiquement les vieux items à BASSE priorité pour refresh.
Quand NE PAS utiliser ça
Ce pattern ajoute de la complexité. Skip-le quand :
- La complétude est requise. Si les systèmes downstream cassent sur des données incomplètes, tu ne peux pas servir des records partiels.
- Le slow path est en fait rapide. Si l'enrichissement prend de manière fiable moins de 100ms, fais-le juste inline.
- Les données arrivent complètes. Si ton upstream fournit des records complets, ne les sépare pas artificiellement.
- Le volume est bas. Si tu traites 100 items par jour, les utilisateurs peuvent attendre des données complètes.
Le takeaway
Pendant des mois, je pensais à mon pipeline comme une chose avec deux vitesses. La partie rapide et la partie lente. Mais elles n'étaient pas deux vitesses d'une chose--c'étaient deux systèmes séparés qui traitaient les mêmes données.
Une fois que je les ai séparés, le fast path est devenu plus rapide (pas de blocage sur les opérations lentes), et le slow path est devenu plus fiable (il pouvait retry et récupérer sans affecter l'index). L'index était parfois incomplet, mais jamais stale.
Trouvable-mais-incomplet bat complet-mais-invisible. À chaque fois.
