Vous scrapez trois sites vendeurs. Les trois listent le même laptop. Vendeur A dit 999€. Vendeur B dit 1 049€. Vendeur C dit 999€ mais affiche "Rupture de stock." Quel prix montrez-vous à vos utilisateurs ?
Ce n'est pas un problème de qualité de données. C'est un problème de confiance. Et dans les systèmes de production qui agrègent plusieurs sources, les données conflictuelles sont la norme, pas l'exception.
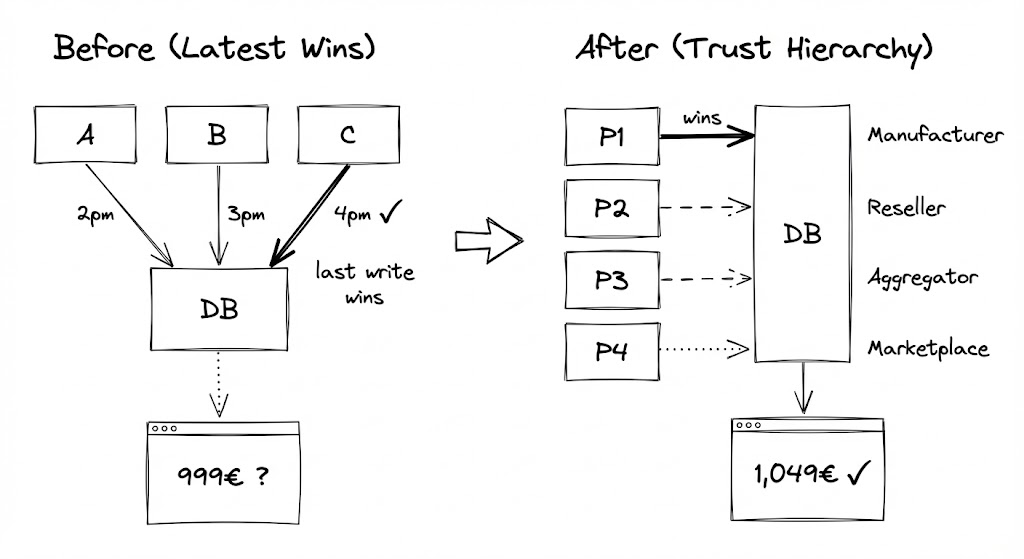
Le problème avec "le plus récent gagne"
L'approche naïve est d'utiliser la valeur la plus récente. Vous scrapez Vendeur A à 14h, Vendeur B à 15h, Vendeur C à 16h. Vendeur C gagne. Votre base dit maintenant que le laptop est en rupture à 999€.
Mais si Vendeur C se trompe ? S'ils sont juste lents à mettre à jour l'inventaire ? Si Vendeur B, malgré son scraping plus tôt, est en fait le distributeur officiel du fabricant avec pricing temps réel ?
Le plus récent gagne échoue car il traite toutes les sources comme égales. Elles ne le sont pas.
Hiérarchies de confiance
Une hiérarchie de confiance est un framework de décision pour résoudre les conflits. Vous assignez à chaque source un niveau de priorité basé sur fiabilité, fraîcheur et autorité. Quand les données sont en conflit, la source de plus haute priorité gagne -- peu importe le timestamp.
Voici comment ça marchait chez Flip :
- Priorité 1 : API Fabricant (temps réel, autoritaire)
- Priorité 2 : Site revendeur autorisé (officiel, mais peut être en retard)
- Priorité 3 : Agrégateur tiers (fiable, mais indirect)
- Priorité 4 : Listings marketplace (qualité variable)
Quand l'API fabricant disait "1 049€, en stock," ça battait tout -- même si un listing marketplace était scrapé 2h plus tard prétendant 999€.
"Les meilleures données ne sont pas les plus récentes. Ce sont les données de la source en qui vous avez le plus confiance."
Implémentation
L'implémentation est plus simple que vous pensez. Ajoutez un champ source_priority à vos métadonnées d'ingestion. Lors du merge des updates, vérifiez la priorité d'abord, le timestamp ensuite.
def merge_product_data(existing, new_data):
if new_data.source_priority > existing.source_priority:
return new_data
elif new_data.source_priority == existing.source_priority:
return new_data if new_data.timestamp > existing.timestamp else existing
else:
return existing
Cela préserve la récence au sein d'un tier de priorité tout en respectant l'autorité de la source entre les tiers.
Quand override
Il y a des cas où vous voulez override la hiérarchie :
- Une source de priorité basse rapporte "discontinued" -- c'est probablement correct
- Plusieurs sources de basse priorité s'accordent sur un changement de prix -- le consensus compte
- Une source haute priorité n'a pas update depuis des jours -- seuil de staleness
Ces edge cases nécessitent une logique custom. Mais pour 95% des conflits, la hiérarchie de confiance suffit.
Pourquoi c'est important
Les hiérarchies de confiance ne sont pas juste pour choisir le "bon" prix. Elles encodent votre connaissance du domaine dans votre modèle de données. Elles rendent la prise de décision de votre système explicite et debuggable.
Quand un utilisateur demande "Pourquoi ce prix est différent de ce que j'ai vu ailleurs ?" vous pouvez répondre : "Nous priorisons les données fabricant sur les listings marketplace." C'est mieux que "Notre scraper a tourné à 16h."
Une bonne architecture data n'est pas de prévenir les conflits. C'est de les résoudre correctement.
