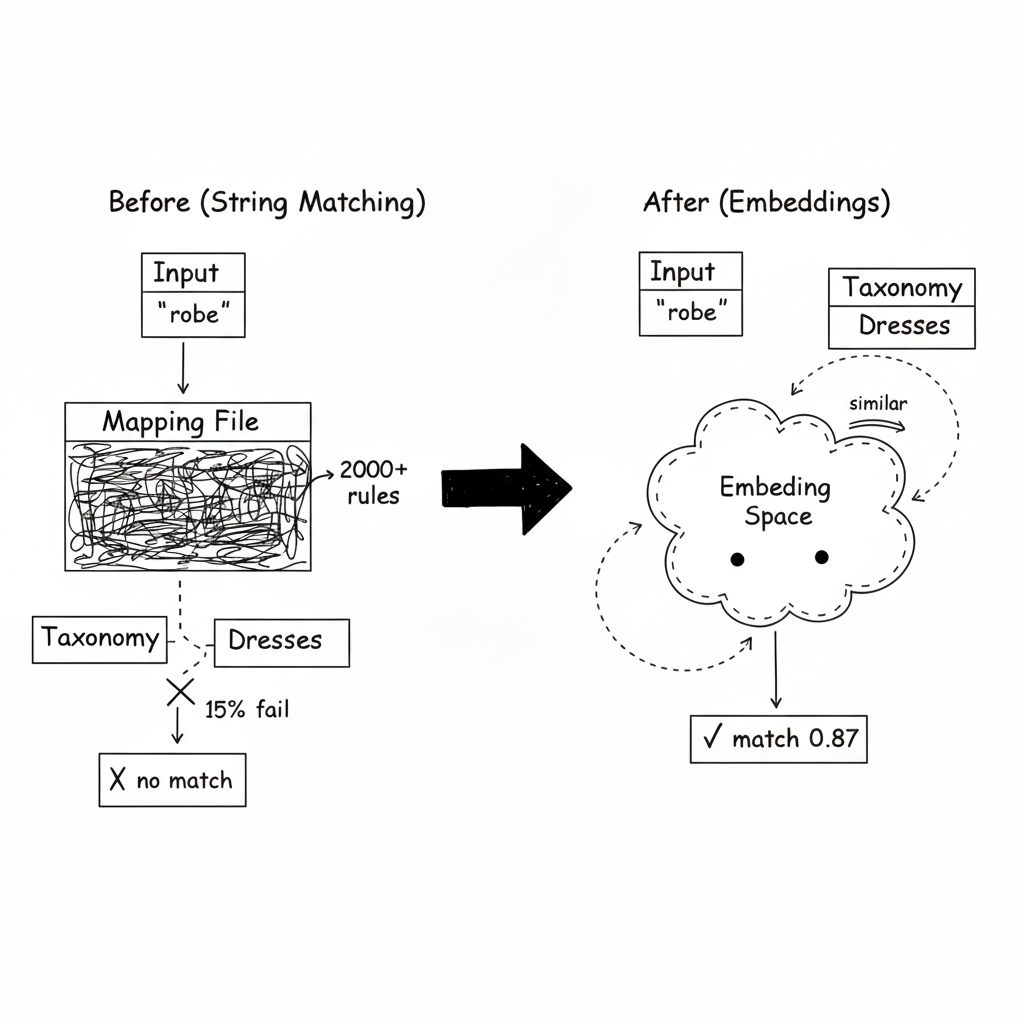
Je fixais un fichier de mapping de 2 000 lignes, et je savais que c'était une bataille perdue d'avance.
Le fichier était censé traduire les labels de produits entrants dans notre taxonomie interne. "T-shirt" -> "Tops > T-Shirts." "Jeans" -> "Bottoms > Pants > Jeans." Assez simple.
Mais ensuite le fournisseur français a commencé à envoyer "pantalon." Et le partenaire UK utilisait "trousers." Et quelqu'un d'autre envoyait "joggers"--qui pouvait être du vêtement de sport ou des pantalons décontractés selon le contexte. Le fichier de mapping a grandi. Les edge cases se sont multipliés. Chaque semaine j'ajoutais de nouvelles entrées, et le taux d'échec restait obstinément à 15%.
Un après-midi, j'ai ajouté la 47ème variation de "dress" au fichier de mapping. Robe. Frock. Gown. Vestido. Kleid. J'ai pris du recul et pensé : il doit y avoir un meilleur moyen.
L'approche évidente (et ses limites)
Le string matching était la première tentative. Si l'input contient "dress," mapper vers "Dresses." Si il contient "pants," mapper vers "Pants."
Ça marchait pour les cas faciles. Ça échouait sur tout le reste : termes français, formes raccourcies, et mots dépendants du contexte.
Donc j'ai ajouté des alias. Puis des patterns regex. Puis des tables de lookup spécifiques par langue. Le fichier de mapping est devenu un monstre--et il échouait toujours 15% du temps parce qu'il y avait toujours une nouvelle variation que je n'avais jamais vue.
La réalisation
Je debuggais une mauvaise classification un jour--quelque chose labellé "robe longue" avait été classifié comme "Unknown"--quand j'ai remarqué quelque chose dans mes logs d'embedding.
J'utilisais des embeddings pour la recherche, et j'avais fait passer le texte d'input par le même modèle d'embedding juste pour le logger. Sur un coup de tête, j'ai tiré l'embedding pour "robe longue" et l'ai comparé à l'embedding pour "dress."
Similarité cosinus : 0.87.
Je suis resté là une minute. Le modèle d'embedding savait que ça voulait dire la même chose. Il avait appris, de millions d'exemples de texte, que "robe" et "dress" apparaissaient dans des contextes similaires. Il n'avait pas besoin d'un fichier de mapping.
"Je n'ai pas besoin d'énumérer chaque input possible. J'ai besoin d'apprendre à ma taxonomie à parler la même langue que les inputs."
L'astuce : embedder votre taxonomie
Voici ce que j'ai construit :
Au lieu de matcher des strings, j'ai converti les deux côtés--l'input ET la taxonomie--dans le même espace d'embedding. Puis la classification est devenue de la recherche de similarité.
Étape 1 : Étendre chaque nœud de taxonomie en un blob de texte riche avec synonymes, traductions, et variations courantes.
Étape 2 : Pré-calculer les embeddings pour chaque nœud de taxonomie au démarrage.
Étape 3 : Quand un input arrive, l'embedder et trouver le nœud de taxonomie le plus proche en utilisant la similarité cosinus.
Maintenant "robe longue" trouve "Dresses" parce que leurs embeddings sont proches--même s'ils ne partagent aucune string commune.
Ce qui m'a surpris
Le modèle connaissait déjà plusieurs langues. Je n'avais pas besoin de fichiers de mapping séparés français et anglais. Les modèles d'embedding modernes sont entraînés sur des données multilingues. "Robe," "dress," "vestido," et "kleid" se regroupent tous naturellement. Une taxonomie, toutes les langues.
La hiérarchie venait gratuitement. Si quelque chose matchait "Pants > Jeans" avec haute confiance, il matchait implicitement "Pants" aussi. J'ai ajouté une propagation de hiérarchie explicite--un match à un nœud feuille booste les ancêtres--mais l'insight de base était déjà là dans les embeddings.
Certaines catégories avaient besoin de seuils plus élevés que d'autres. Une similarité cosinus de 0.7 veut dire différentes choses selon la catégorie. Matcher une catégorie large comme "Clothing" est facile--beaucoup de choses sont des vêtements. Matcher une catégorie spécifique comme "Slim Fit Jeans" requiert plus de confiance parce qu'il y a tellement d'alternatives similaires.
J'ai fini avec des seuils conscients de la profondeur : catégories top level utilisent 0.55, niveau moyen utilise 0.65, et niveau feuille utilise 0.75. Les catégories plus profondes ont besoin de plus de confiance pour matcher.
Les détails production
Pré-calculer tout. Embedder les nœuds de taxonomie au démarrage prend quelques secondes. Cacher les embeddings d'input évite de re-embedder le même texte à répétition.
Gérer les paires confuses explicitement. Certaines catégories sont sémantiquement proches mais devraient être distinctes. "Costumes" et "Dresses" se chevauchent dans l'espace d'embedding--ce sont tous deux des vêtements que les gens portent. J'ai ajouté des exemples négatifs pour les éloigner.
Construire une boucle de feedback. Quand un humain corrige une classification, j'ajoute le terme mal classifié au texte d'expansion de la bonne catégorie. La taxonomie devient plus intelligente avec le temps.
Versionner vos embeddings. Si vous changez de modèles d'embedding, tous vos embeddings de taxonomie ont besoin de régénération. Trackez quelle version de modèle a créé quels embeddings.
Quand NE PAS utiliser ça
- Un input structuré existe déjà. Si les données arrivent avec des IDs de catégorie, mappez-les directement.
- Un match exact est requis. La similarité sémantique est floue. Pour des raisons légales ou de conformité, vous pourriez avoir besoin d'une revue humaine.
- La taxonomie change constamment. Re-embedder toute la taxonomie est coûteux. Ça marche mieux quand la taxonomie est stable.
- Nœuds de taxonomie sparse. Les catégories d'un seul mot comme "Other" ou "Miscellaneous" ne produisent pas d'embeddings significatifs.
Le takeaway
J'ai passé des semaines à maintenir un fichier de mapping de 2 000 lignes qui échouait toujours 15% du temps. L'approche par string-matching était condamnée parce que j'essayais d'énumérer un espace infini d'inputs possibles.
L'approche par embedding a inversé le problème. Au lieu de lister chaque variation d'input, j'ai appris à la taxonomie à comprendre le sens. Le modèle avait déjà appris que "robe" et "dress" étaient liés--j'avais juste besoin de poser la bonne question.
Le fichier de mapping est parti maintenant. Le taux d'échec est passé sous les 2%. Et quand quelqu'un envoie une nouvelle variante de langue que je n'ai jamais vue, ça marche généralement juste.
