L'erreur était cryptique : CUDA error: out of memory.
J'ai vérifié le GPU. Plein de VRAM disponible--16GB, seulement 4GB utilisés par le modèle. Plein de marge.
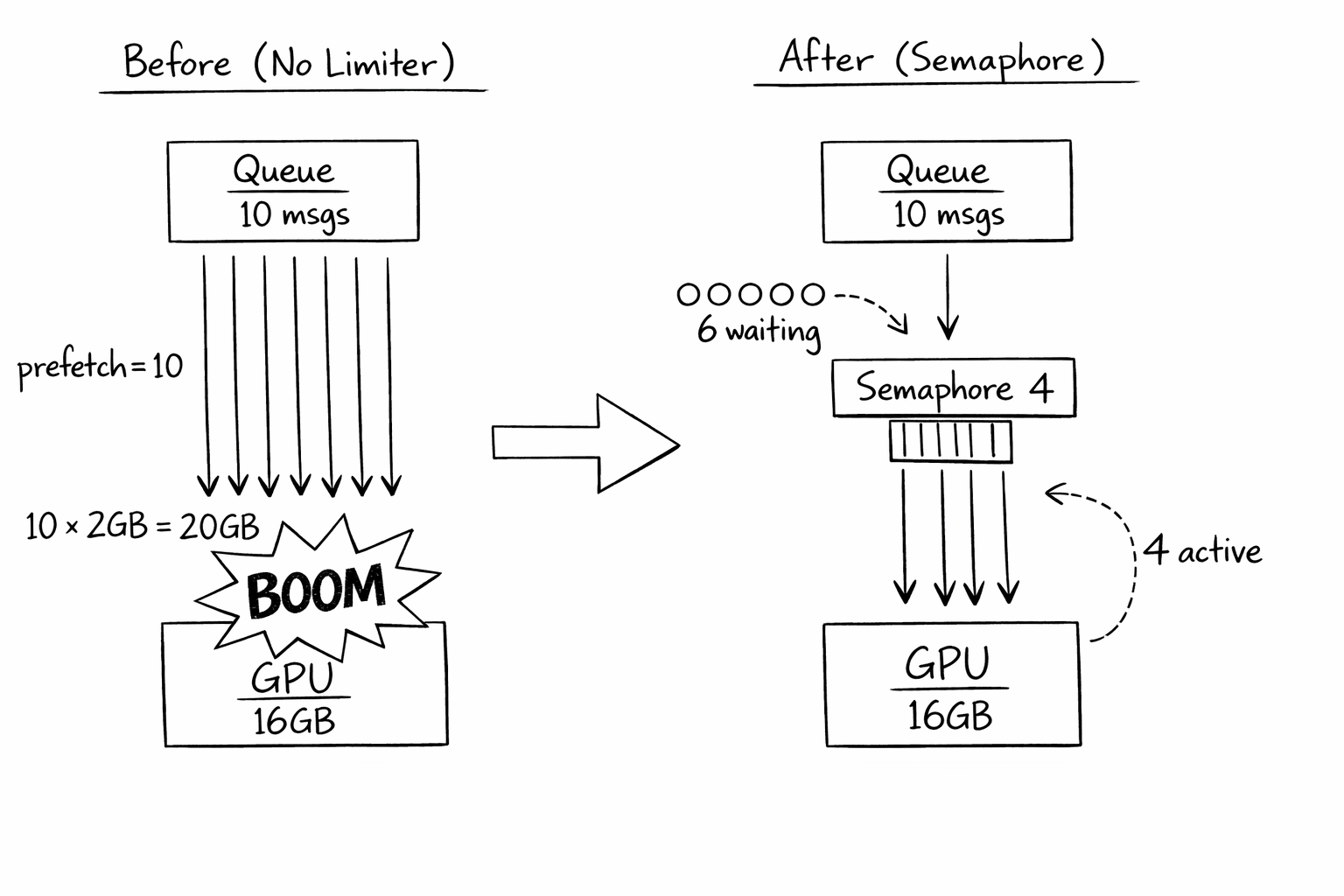
Puis j'ai regardé la liste de processus. Dix requêtes d'inférence tournaient simultanément. Chacune avait besoin de 2GB de working memory pour le batch processing. Dix fois deux font vingt. J'avais seize.
Les maths ne marchaient pas. Et rien ne l'avait dit.
Le setup
J'utilisais une message queue avec prefetch. Pattern standard : tirer plusieurs messages à la fois, les processer en parallèle, acknowledger quand fini. Plus de throughput. Moins de temps idle.
Ça marche super pour le travail CPU-bound. Dix requêtes web ? Dix queries database ? Pas de problème. L'OS gère le scheduling. La mémoire est pas chère. Ajoutez plus de threads.
Mais la mémoire GPU n'est pas comme la mémoire CPU. Vous ne pouvez pas la swapper. Vous ne pouvez pas la pager. Quand elle est pleine, elle est pleine. Et mon code tirait 10 messages, lançait 10 opérations GPU, et explosait.
Le fix naïf (et pourquoi ce n'était pas assez)
Première tentative : réduire prefetch à 1. Ça a "fixé" l'OOM. Mais maintenant je processais un message à la fois. Mon GPU était idle à 90%. Le throughput s'est effondré.
Le problème : prefetch contrôle combien de messages la queue me donne. Mais elle ne sait rien de mon GPU. Mettre prefetch à 4 (la limite GPU) était une coïncidence--si mon modèle changeait pour avoir besoin de 3GB par requête, je devrais me rappeler de mettre à jour prefetch.
Et prefetch affecte le comportement de la queue d'autres façons. Si je ne peux pas processer assez vite, je retiens les messages en otage. Les autres consommateurs ne peuvent pas les prendre. Mettre prefetch basé sur les contraintes GPU mélangeait les concerns.
La réalisation
Je devais découpler deux choses : l'acquisition de messages (combien de messages je tire de la queue) et le processing concurrent (combien je process réellement à la fois).
La queue devrait me donner des messages aussi vite que je peux les gérer. Mais je devrais contrôler combien tournent réellement en parallèle.
Enter le sémaphore. Maintenant je peux prefetch 10 messages (gardant la queue contente), mais seulement 4 processent simultanément (gardant le GPU content). Quand un finit, le prochain message en attente démarre.
"Prefetch est à propos du comportement de la queue. Les sémaphores sont à propos du comportement des ressources. Ce n'est pas la même chose."
Le calcul du budget
Comment je savais que "4" était le bon nombre ? J'ai fait les maths :
- GPU VRAM : 16GB
- Modèle chargé : 4GB
- Working memory par inférence : 2GB
- System overhead : 2GB
- Disponible pour les batches : 16 - 4 - 2 = 10GB
- Max concurrent : 10GB / 2GB = 5, mais arrondir en bas pour sécurité -> 4
J'ai aussi ajouté du monitoring pour valider. Si "before inference" montrait jamais moins de 2GB libre, je saurais que mon budget était faux.
Ce que j'ai mal fait initialement
J'ai hardcodé la limite. Quand j'ai upgradé vers un GPU 24GB, j'ai oublié de mettre à jour MAX_CONCURRENT. Je laissais 8GB inutilisés. Maintenant je calcule dynamiquement depuis la mémoire disponible.
Je n'ai pas pris en compte les inputs de taille variable. Certaines images étaient plus grosses que d'autres. Les petites images avaient besoin de 1GB de working memory ; les grosses 4GB. Avec MAX_CONCURRENT=4 et quatre grosses images, j'avais quand même OOM. Je suis passé à un sémaphore de tracking mémoire qui s'adapte à la taille réelle du workload.
J'ai oublié les timeouts. Si une requête hang, elle tient le sémaphore pour toujours. Les autres requêtes s'enfilent. Finalement le consommateur a l'air mort même s'il est juste bloqué. Maintenant les requêtes ont des timeouts et relâchent le sémaphore sur timeout.
Je ne gérais pas l'épuisement du sémaphore gracieusement. Quand les 4 slots étaient pleins et que plus de messages arrivaient, ils s'enfilaient en mémoire. Pendant les pics de trafic, cette queue croissait sans limite. J'ai ajouté du backpressure : si je ne peux pas obtenir un slot en 10 secondes, je rejette le message. Il retourne à la queue pour retry.
Le pattern généralisé
L'insight clé : prefetch est à propos du comportement de la queue, le sémaphore est à propos du comportement des ressources. Définissez-les indépendamment.
Calculez la limite de ressource depuis le hardware. Créez un sémaphore avec cette limite. Prefetch peut être 2x la limite. Avant de processer chaque message, acquérez le sémaphore avec un timeout. Si timeout, rejetez et requeued le message. Après processing, relâchez le sémaphore.
La checklist
Si vous implémentez ça :
- Identifier votre ressource limitante (GPU VRAM, file handles, connections, etc.)
- Calculer la concurrence maximale depuis le budget ressource, pas deviner
- Utiliser des sémaphores pour forcer la concurrence indépendamment du prefetch
- Ajouter des timeouts pour empêcher les requêtes hung de bloquer pour toujours
- Implémenter du backpressure pour quand le sémaphore est épuisé
- Monitor l'usage réel des ressources pour valider votre budget
- Recalculer les limites quand le hardware change
- Considérer les workloads de taille variable (memory-tracking pools)
Le takeaway
Pendant des années, je pensais que les limites de concurrence étaient à propos des CPUs. Combien de threads peuvent tourner ? Combien de cores j'ai ? L'OS gère le reste.
Mais la mémoire GPU ne marche pas comme ça. Les connexions réseau ne marchent pas comme ça. Les file handles ne marchent pas comme ça. Toute ressource contrainte qui ne peut pas être swappée ou pagée a besoin de gestion explicite.
La queue me disait de processer 10 messages. Le GPU pouvait seulement gérer 4. Personne ne traduisait entre eux jusqu'à ce que j'ajoute le sémaphore.
Maintenant la queue et le GPU parlent des langues différentes, et le sémaphore traduit. La queue pense que je process 10. Le GPU en voit 4 à la fois. Tout le monde est content.
