Le nouveau modèle d'embedding était 15% meilleur sur nos benchmarks. Temps de tout re-embedder.
J'ai écrit le script de migration : sélectionner tous les items, générer de nouveaux embeddings, mettre à jour l'index. Assez simple. Je l'ai lancé, suis allé déjeuner, suis revenu vérifier le progrès.
C'est là que je l'ai vu. La moitié des items étaient skippés avec le message : "Embedding unchanged--exact same vector."
Étrange. Le nouveau modèle devrait produire des vecteurs différents. J'ai creusé. Il s'avère que j'avais déjà lancé le nouveau modèle sur la moitié du catalogue pendant les tests la semaine dernière. Ces items avaient des embeddings v2. Mais mon script de migration ne savait pas ça. Il a re-embeddé tout, remarqué que les vecteurs matchaient, et skippé l'update. Mais il avait quand même calculé l'embedding d'abord--brûlant des cycles GPU pour produire des résultats identiques.
Je venais de gaspiller 90 minutes à processer des items qui étaient déjà à jour.
L'approche naïve
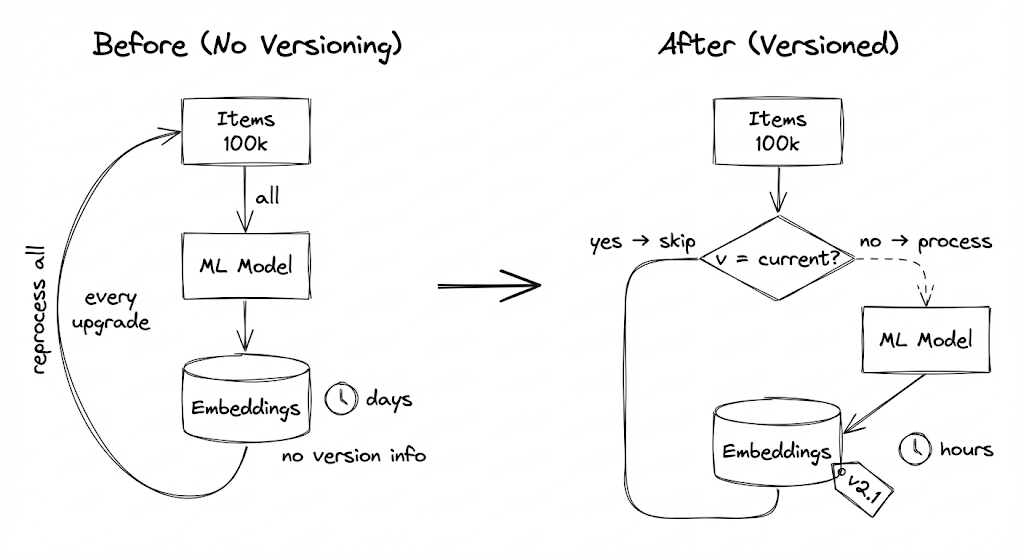
Mon pipeline original ne trackait pas les versions de modèle. Il stockait juste les embeddings. Pour vérifier si un item avait besoin de retraitement, je devais régénérer l'embedding et comparer. Ce qui va à l'encontre du but.
Donc je faisais ce que la plupart des gens font : juste tout re-embedder quand le modèle change. Chaque upgrade de modèle signifiait un run de retraitement complet. Des centaines de milliers d'items x 10 secondes chacun = des jours de temps GPU par migration.
On upgradait les modèles seulement quand absolument nécessaire. La douleur du re-embedding signifiait qu'on restait coincés sur des vieux modèles plus longtemps qu'on aurait dû.
La réalisation
J'expliquais le problème à un collègue, et il a demandé : "Pourquoi tu ne vérifies pas juste la version avant de processer ?"
J'ai commencé à expliquer pourquoi c'était compliqué... et puis je me suis arrêté. Ce n'était pas compliqué. Je ne l'avais juste pas fait.
Le changement mental : les outputs ML devraient être versionnés comme tout autre artifact. Vous ne redéploieriez pas du code inchangé. Pourquoi régénérer des embeddings inchangés ?
J'ai ajouté le tracking de version de modèle. Maintenant avant de processer, je vérifie : si l'item n'a pas d'embedding, le processer. Si la version d'embedding ne matche pas la version actuelle, le processer. Sinon, le skipper.
L'upgrade de modèle devient : processer les items où embedding_version != CURRENT_VERSION. Les items déjà processés sont skippés sans computation.
"Les outputs ML sont des artifacts, pas de la computation éphémère. Versionnez-les comme du code."
Ce que j'ai mal fait initialement
Je ne trackais que le nom du modèle. Quand j'ai patché un bug dans l'étape de preprocessing (v1.0 -> v1.1), les embeddings avec l'ancien preprocessing avaient besoin de régénération. Mais ma vérification regardait seulement le nom du modèle. J'ai dû ajouter une string de version complète.
J'ai oublié le processing échoué. Certains items échouaient pendant l'embedding--mauvaises images, timeouts. Je stockais des embeddings null avec version "2.0.0". Ma vérification disait "already current" et les skippait pour toujours. Maintenant je tracke le statut de processing séparément avec trois états : success, failed, et pending.
Les items avec status = "failed" peuvent être retriés. Les items avec status = "success" ET version = CURRENT_VERSION sont skippés.
Je n'ai pas pris en compte les dépendances. Mon embedding dépend de l'image. Si l'image change, l'embedding est stale--même si la version du modèle matche. J'ai ajouté un hash de l'input. Si l'URL de l'image change, le hash change, et on re-embed même si le modèle est le même.
J'ai rendu les versions trop granulaires. Au début, je bumpais la version pour chaque petit changement. Bientôt j'avais v1.0.0, v1.0.1, v1.0.2... v1.0.47. Seuls certains changements affectaient réellement l'output. J'ai commencé à distinguer les changements "compatibles" et "breaking". Maintenant je bump seulement quand les outputs diffèrent réellement.
Le bonus : le rollback devient possible
Avant le versioning, rollback un modèle était terrifiant. Je devais re-embedder tout avec l'ancien modèle. Si l'ancien modèle était pire pour certains items mais meilleur pour d'autres, je n'avais aucun moyen de savoir lesquels.
Maintenant je peux voir exactement quels items ont été processés par quelle version. Je peux re-run des batches spécifiques. Je peux A/B tester des modèles sur des subsets. Je peux même garder plusieurs versions dans l'index et router les queries vers différentes.
Le versioning a transformé "migration irréversible" en "expérience réversible."
La checklist
Si vous implémentez ça :
- Stocker le nom et la version du modèle avec chaque output
- Tracker le statut de processing (success/failed/pending) séparément de l'output
- Hasher les inputs pour détecter quand les données source changent
- Définir ce qui constitue un changement de version "breaking"
- Écrire des queries pour trouver les items nécessitant reprocessing
- Considérer garder les versions précédentes pour rollback
- Ajouter des métriques : quel pourcentage est à jour ? Combien en pending ?
- Configurer des alertes pour les pics de processing échoué
Le takeaway
Trop longtemps, j'ai traité les outputs de modèle ML comme de la computation éphémère. Besoin d'embeddings ? Lance le modèle. Besoin de nouveaux embeddings ? Relance le modèle sur tout.
Mais les embeddings sont des artifacts. Ils ont été produits par une version de modèle spécifique, depuis un input spécifique, à un moment spécifique. Tracker cette provenance signifie que vous pouvez skip le travail redondant, retry les échecs, et rollback les mauvais changements.
Maintenant quand j'upgrade des modèles, je process seulement ce qui est réellement outdated. Une migration à grande échelle qui prenait des jours prend maintenant des heures--parce que la plupart des items étaient déjà à jour depuis les tests.
Versionnez vos outputs ML. Vous vous remercierez pendant le prochain upgrade de modèle.
