Le GPU a manqué de mémoire à 3h du matin. Quand je me suis réveillé, 10 000 items étaient bloqués dans une queue de retry, et le pipeline de traitement était gelé depuis six heures.
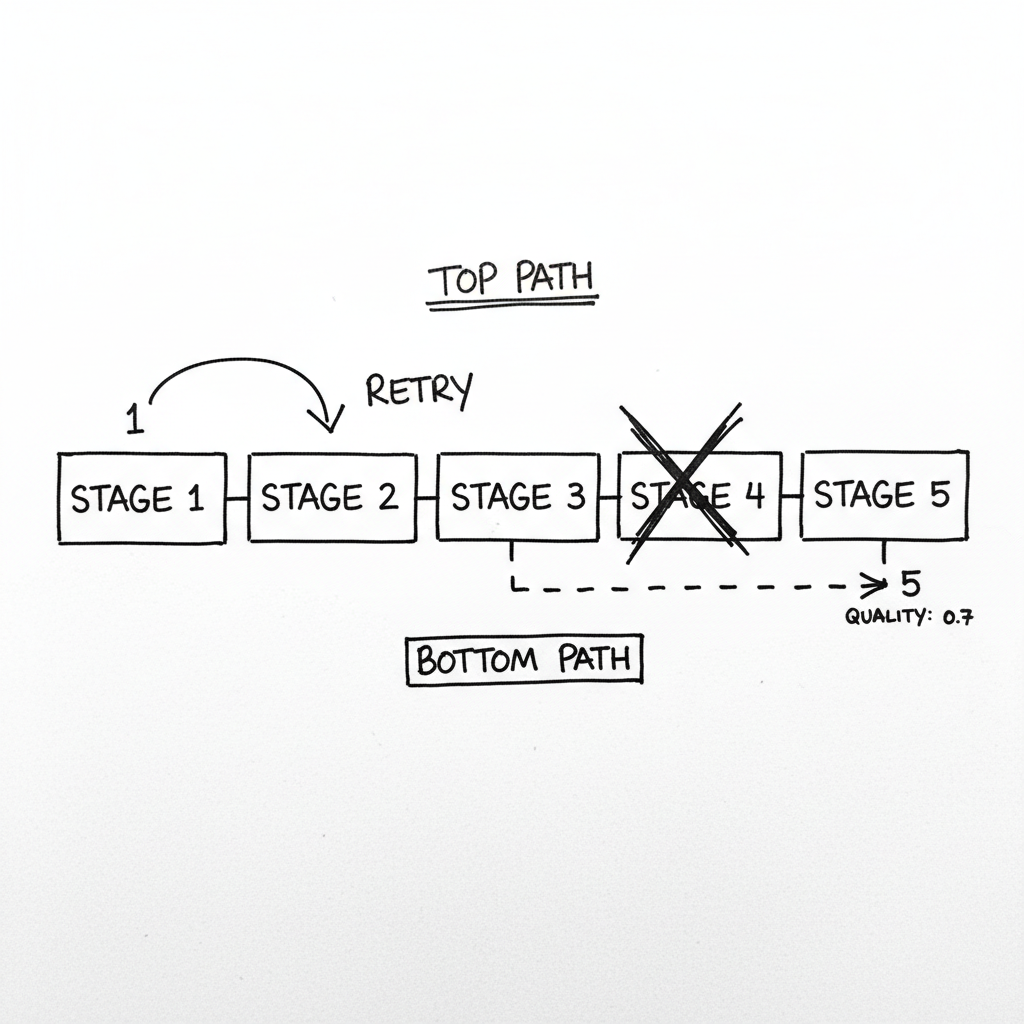
La partie frustrante ? Les étapes 1 à 3 étaient déjà complétées pour tous ces items. Ils avaient été récupérés, validés, et partiellement enrichis. Mais l'étape 4--l'étape de classification d'image--avait échoué. Et parce que mon pipeline était construit comme une chaîne linéaire, un échec à l'étape 4 signifiait que tout ce qui suivait ne s'exécutait jamais.
J'ai passé la matinée à vider la queue de retry, regardant les items passer un par un. Et je continuais à penser : la plupart de ces items n'avaient même pas besoin de classification d'image. C'était un nice-to-have. Pourquoi est-ce que je bloquais tout sur un nice-to-have ?
Le piège du tout-ou-rien
Mon pipeline original ressemblait à ça : fetch, validate, extract text, classify image, generate embedding, store. Propre. Simple. Et complètement faux pour la production.
Quand l'étape 4 échouait, je ne perdais pas que l'étape 4. Je perdais tout le travail des étapes 1-3. Ces items allaient dans une queue de retry où ils recommençaient depuis l'étape 1. Compute gaspillé. Temps gaspillé.
Encore pire : quand l'étape 4 échouait pour beaucoup d'items (comme pendant un problème de mémoire GPU), la queue de retry grandissait plus vite que je ne pouvais la vider. Tout le système se figeait.
La réalisation
J'expliquais le problème à quelqu'un, et il a demandé : "Que se passe-t-il si tu... skip juste l'étape 4 ?"
Ma première réaction était : "Alors les données seraient incomplètes !"
Mais ensuite j'y ai réfléchi. Des données incomplètes sont quand même des données. Un produit sans classification d'image peut quand même être recherché par nom. Un document sans embedding peut quand même être trouvé par mot-clé. La classification rendait les résultats meilleurs, mais son absence ne les rendait pas impossibles.
"Un succès partiel n'est pas la même chose qu'un échec. C'est un état valide--tant que vous le trackez."
Le nouveau modèle : chaînes de fallback
Au lieu de traiter chaque étape comme pass/fail, j'ai donné à chaque étape une chaîne de fallback. La classification d'image pouvait fallback sur un modèle CPU (plus lent), puis des heuristiques basées sur des règles, puis skip entièrement avec une confiance de zéro.
Voici l'insight clé : chaque étape devrait avoir une option "skip" comme dernier fallback. Parfois la bonne réponse est "Je ne sais pas"--mais le dire explicitement est mieux que bloquer tout le pipeline.
Tracker la dégradation
La partie délicate : vous ne pouvez pas juste dégrader silencieusement. Les systèmes downstream ont besoin de savoir ce qu'ils reçoivent.
J'ai ajouté des scores de qualité qui décroissent quand des fallbacks sont utilisés. Si la classification (0.9 penalty) et l'embedding (0.8 penalty) ont tous deux utilisé des fallbacks, le score de qualité final est 1.0 x 0.9 x 0.8 = 0.72.
Maintenant les systèmes downstream peuvent prendre des décisions informées. La recherche peut classer les items haute qualité au-dessus des items basse qualité. Un dashboard peut montrer la distribution de qualité. Une queue de retry peut prioriser les items avec basse qualité pour retraitement quand la capacité revient.
La différence entre les états null
Ça m'a pris du temps à bien faire. Quand un champ est null, ça peut vouloir dire plusieurs choses : pas encore traité, échoué, non applicable, ou délibérément skippé.
Ce sont des états très différents, et les traiter tous comme "null" mène à des cauchemars de debugging.
Maintenant chaque résultat d'étape inclut un statut explicite avec la valeur réelle, l'indicateur de statut, le message d'erreur si présent, quel fallback a été utilisé, et si un retry est possible.
Ce qui m'a eu en production
Les circuit breakers sont essentiels. La première fois que l'API externe est tombée, ma logique de fallback continuait à la marteler. Chaque item essayait le primaire, échouait, puis utilisait le fallback. Ça fait beaucoup de requêtes échouées. Maintenant j'utilise des circuit breakers : si une étape échoue N fois en M minutes, skip direct vers le fallback pendant un moment.
Queues de retry pour les items basse qualité. Les items qui ont utilisé des fallbacks devraient être retraités quand le chemin primaire récupère. Je queue tout item avec score de qualité < 0.8 pour retry éventuel à priorité LOW.
Certains fallbacks sont incompatibles. Si l'étape 3 utilise fallback A, l'étape 5 pourrait avoir besoin du fallback B pour maintenir la cohérence. Je documente ces contraintes explicitement et les applique dans la logique de merge.
Tester les chemins de fallback. Ça semble évident, mais je n'avais testé que le happy path. Quand le GPU a vraiment échoué, j'ai découvert que mon "CPU fallback" n'avait jamais été exécuté en production et avait un bug subtil. Maintenant j'ai un test hebdomadaire qui force le mode fallback sur un échantillon d'items.
Quand NE PAS utiliser ça
- La correction est obligatoire. Calculs financiers, systèmes de sécurité--vous ne pouvez pas servir des données "à peu près correctes".
- La qualité est votre produit. Si les utilisateurs paient pour des résultats haute qualité, un output dégradé endommage votre proposition de valeur.
- Les étapes sont étroitement couplées. Si l'étape 5 assume que l'étape 3 a réussi, vous ne pouvez pas skip l'étape 3 sans réécrire l'étape 5.
- Le budget de complexité est dépensé. Chaque chemin de fallback est une chose de plus à tester et maintenir. Si vous luttez déjà avec la complexité, plus de chemins n'aideront pas.
Le takeaway
Pendant des mois, j'ai traité mon pipeline comme une chaîne où chaque maillon devait tenir. Une cassure, et toute la chaîne échouait. Les items s'empilaient dans les queues de retry. Les pannes cascadaient.
Maintenant j'y pense différemment : chaque étape soit réussit, fallback, ou skip--et chaque résultat est valide, juste avec une qualité différente. Le pipeline avance toujours. Les items sont toujours traités. Le score de qualité vous dit à quel point vous pouvez faire confiance au résultat.
Quand le GPU échoue à 3h du matin maintenant, je ne me réveille pas avec 10 000 items bloqués. Je me réveille avec 10 000 items traités avec un score de qualité de 0.7. Pas parfait. Mais traités. Cherchables. Disponibles.
C'est la différence entre un pipeline qui tourne en production et un qui tourne en théorie.
