La queue de retry avait 50 000 items. Tous échouaient. Tous réessayaient. Tous échouaient encore.
J'ai fouillé dans les logs. La même erreur, encore et encore : "Failed to parse product data." La structure de la page avait changé. Mon parser cherchait un div qui n'existait plus.
Voilà le truc : ces 50 000 retries n'allaient jamais fonctionner. Le site web avait changé. Réessayer ne le réparerait pas. Mais ma logique de retry ne savait pas ça. Elle voyait juste "erreur" et pensait "réessayer."
Pendant ce temps, les timeouts réseau légitimes--des erreurs qui réussiraient au retry--étaient coincées derrière 50 000 tentatives vouées à l'échec.
L'approche naïve
Ma première logique de retry était simple : chaque erreur recevait le même traitement--attendre 30 secondes, réessayer, jusqu'à 5 fois.
Ça marche bien quand la plupart des erreurs sont transitoires. Blip réseau ? Retry. Serveur surchargé ? Retry. Réussit généralement à la deuxième ou troisième tentative.
Mais toutes les erreurs ne sont pas transitoires.
La réalisation
Je debuggais les échecs de parsing quand j'ai remarqué quelque chose dans mes logs. Il y avait en fait quatre types d'erreurs distincts mélangés :
- Timeouts réseau - Le serveur n'a pas répondu à temps
- Rate limits (429) - On frappe l'API trop vite
- Blocks (403) - Notre IP a été flaggée
- Erreurs de parsing - La structure de la page a changé
Chaque type a des caractéristiques de retry complètement différentes. Les traiter tous pareil était l'erreur. Une erreur de parsing réessayée 5 fois gaspille des ressources sur quelque chose qui ne réussira jamais. Un rate limit réessayé après 5 secondes se fait juste rate limiter encore.
Le pattern : catégories d'erreurs avec stratégies adaptées
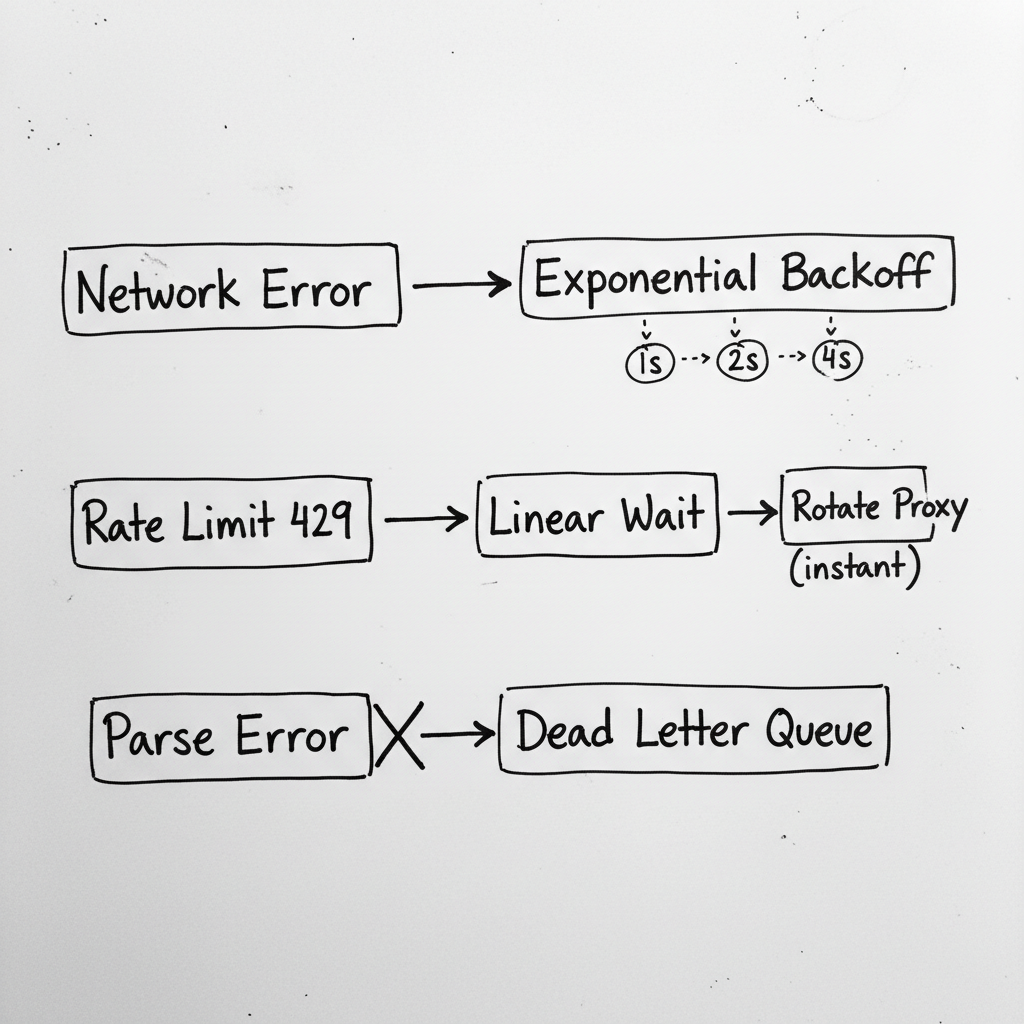
J'ai créé un système de catégorisation d'erreurs avec des stratégies par catégorie. Les erreurs réseau ont un backoff exponentiel et rotation de proxy. Les rate limits ont un backoff linéaire et respectent les headers Retry-After. Les blocks ont rotation immédiate de proxy et alertes. Les erreurs de parsing ne retry pas du tout--elles vont direct à la dead letter queue.
"Toutes les erreurs ne sont pas égales. Ne les traitez pas comme si elles l'étaient."
Ce que j'ai mal fait initialement
J'ai oublié les cascading failures. Quand le serveur upstream est tombé, j'ai soudain eu des milliers d'erreurs réseau. Mon système d'alertes a envoyé 500 emails en 10 minutes. J'ai ajouté du rate limiting aux alertes : une alerte par catégorie par heure.
Je ne distinguais pas "retry plus tard" et "ne pas retry". Certaines erreurs de parsing sont en fait réparables au retry--si la page était partiellement chargée. Mais les changements structurels sont permanents. J'ai ajouté des sous-catégories pour parsing transitoire vs structurel.
J'avais hardcodé les stratégies. Quand les rate limits ont changé, j'ai dû redéployer pour corriger le délai. Maintenant les stratégies sont configurables via variables d'environnement.
J'ignorais le header Retry-After. Les réponses rate limit vous disent souvent exactement combien de temps attendre. Je l'ignorais et utilisais mon propre délai. Maintenant je respecte le header quand présent.
La checklist
Si vous implémentez ça :
- Définir des catégories d'erreurs claires (réseau, rate limit, auth, parsing, etc.)
- Définir des limites de retry par catégorie (certaines devraient être 0)
- Choisir des stratégies de backoff appropriées (exponentiel pour réseau, linéaire pour rate limits)
- Ajouter des actions de rotation/mitigation par catégorie (rotation proxy, credential refresh)
- Définir des seuils d'alerte par catégorie (immédiat pour blocks, jamais pour rate limits attendus)
- Rate-limiter vos alertes pour éviter le spam en cascade
- Respecter les headers Retry-After quand présents
- Tracker les métriques par catégorie (quel pourcentage d'erreurs sont parsing vs réseau ?)
Le takeaway
Pendant des mois, ma logique de retry traitait chaque erreur comme si elle pouvait être transitoire. Timeouts réseau, rate limits, échecs de parsing--tous recevaient 5 retries avec 30 secondes de délai.
Le résultat était du gaspillage. Les erreurs de parsing retry jusqu'à mourir. Les rate limits retry trop vite. Les erreurs réseau qui auraient réussi rapidement se retrouvaient coincées derrière des milliers de tentatives sans espoir.
Maintenant les erreurs sont catégorisées d'abord, puis gérées selon leur nature. Les erreurs de parsing vont direct à la dead letter queue. Les rate limits attendent le bon temps. Les erreurs réseau changent de proxies. La queue se vide plus vite. Les alertes sont significatives.
