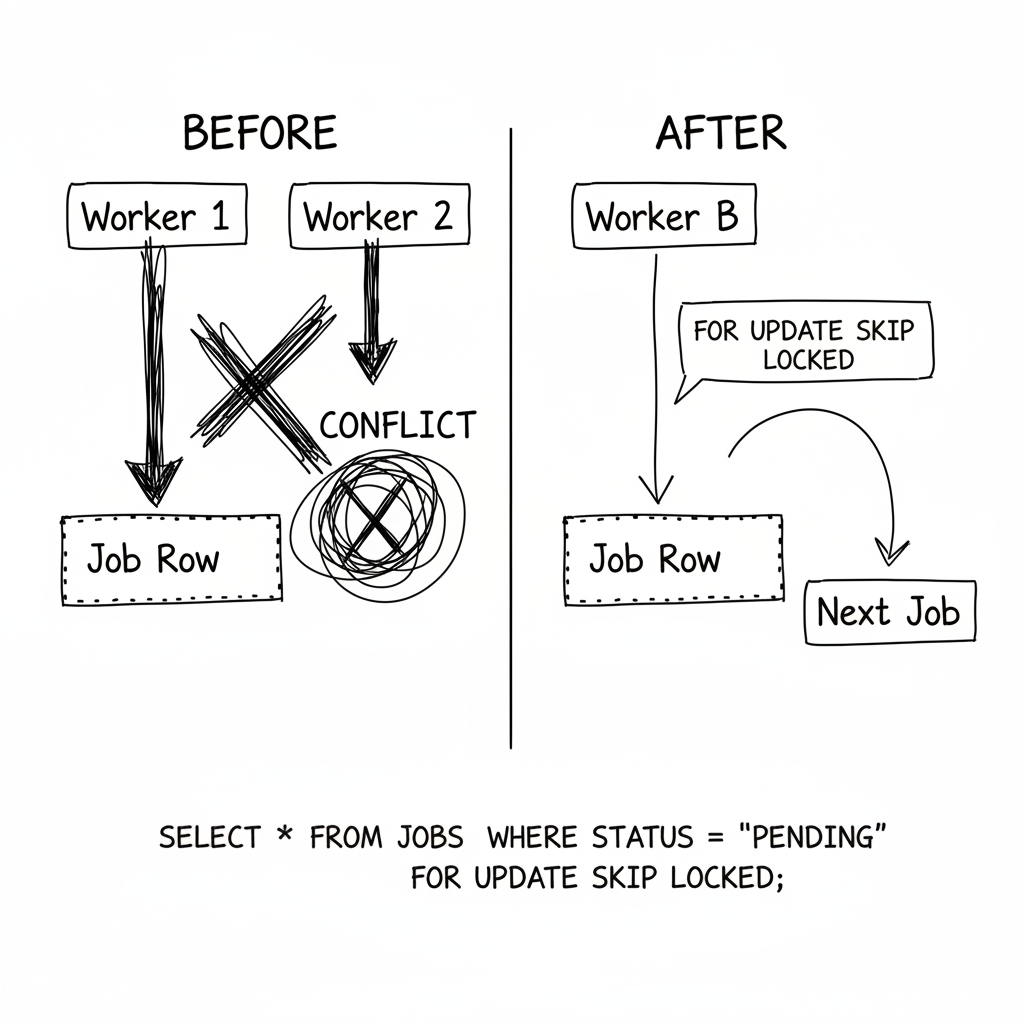
Deux workers. Un job. Les deux l'ont réclamé.
J'ai regardé les logs incrédule. Worker A a pris le job #4521. Worker B a pris le job #4521. Ils ont tous les deux commencé à traiter. Ils ont tous les deux fini. Le résultat de Worker A a été sauvegardé. Puis le résultat de Worker B l'a écrasé.
Les données étaient corrompues--un mélange bizarre de deux runs de traitement différents. Et ce n'était pas une race condition rare. Ça arrivait des dizaines de fois par heure.
Ma première pensée : "J'ai besoin d'un verrou distribué. Il est temps d'ajouter Redis."
Le fix évident (et pourquoi je ne l'ai pas utilisé)
Les verrous distribués sont la réponse classique. Avant de traiter, acquérir un verrou. Quand fini, le relâcher. Redis rend ça facile avec SETNX. Redlock le rend "safe." Chaque tutoriel vous pointe là.
Mais j'ai hésité. J'avais déjà une base de données. Ajouter Redis signifiait : un autre service à déployer et monitorer, un autre mode de défaillance (que se passe-t-il si Redis tombe ?), des edge cases d'expiration de verrou (que se passe-t-il si le traitement prend plus longtemps que le TTL ?), et des round-trips réseau supplémentaires pour chaque job.
J'ai fixé ma table de queue de jobs. Elle avait une colonne status : pending, processing, completed, failed. Les workers sélectionnaient les jobs où status égale 'pending', puis les mettaient à jour vers 'processing'.
Le problème était évident : le SELECT et l'UPDATE étaient deux opérations séparées. Entre les deux, un autre worker pouvait prendre le même job.
Puis ça a fait tilt. Et si elles n'étaient pas séparées ?
L'astuce : rendre la sélection et le verrouillage atomiques
Au lieu de deux opérations (SELECT puis UPDATE), je les ai combinées en une opération atomique en utilisant FOR UPDATE SKIP LOCKED.
UPDATE jobs
SET status = 'processing', worker_id = 'worker-A', started_at = NOW()
WHERE id = (
SELECT id FROM jobs
WHERE status = 'pending'
ORDER BY priority, created_at
LIMIT 1
FOR UPDATE SKIP LOCKED
)
RETURNING *
La magie est dans FOR UPDATE SKIP LOCKED. Ça veut dire : "Verrouille la row que je sélectionne, mais si elle est déjà verrouillée par quelqu'un d'autre, skip-la et trouves-en une autre."
Maintenant quand deux workers font la course pour le même job : l'UPDATE de Worker A réussit, retourne le job. La sous-requête de Worker B skip la row verrouillée, trouve le prochain job pending à la place.
Pas de Redis. Pas de verrous distribués. Juste du SQL faisant ce que le SQL fait bien.
Ce que j'ai mal fait initialement
J'ai oublié les workers qui crashent. Si un worker prend un job et meurt ensuite, le job reste 'processing' pour toujours. Personne d'autre ne le prendra.
J'ai ajouté une requête de cleanup qui tourne toutes les quelques minutes pour reset les jobs bloqués en 'processing' depuis plus de 30 minutes vers 'pending'.
Je ne trackais pas les tentatives. Quand un job échoue et est retenté, j'ai besoin de savoir combien de fois il a échoué. Sinon, les jobs cassés réessayent pour toujours. Maintenant j'incrémente un compteur de tentatives et ne prends que les jobs en dessous de max_attempts.
J'ai rendu le timeout trop court. Certains jobs prennent légitimement 25 minutes. Mon timeout de 30 minutes les resetait alors qu'ils tournaient encore. Maintenant je tracke last_heartbeat et les workers le mettent à jour périodiquement. La requête de cleanup vérifie le heartbeat, pas le temps de démarrage.
Le pattern généralisé
L'insight clé : vous pouvez utiliser un UPDATE conditionnel comme un verrou optimiste. L'UPDATE ne réussit que si la condition est toujours vraie.
"Chaque UPDATE est déjà atomique. Chaque clause WHERE est déjà une condition. J'avais juste besoin de les combiner en une seule instruction."
Pour réclamer du travail : update status vers 'processing' où le job est encore pending, en utilisant FOR UPDATE SKIP LOCKED. Pour compléter du travail : update status vers 'completed' où le job est encore 'processing'. Pour échouer du travail : update status basé sur le compteur de tentatives--retour vers 'pending' si en dessous de max tentatives, sinon 'failed'.
Quand NE PAS utiliser ça
- Coordination cross-database. Si le verrou et le travail sont dans des bases de données différentes, vous avez besoin d'une vraie coordination distribuée.
- Exigences de latence sub-milliseconde. Les round-trips database ajoutent de la latence. Pour le trading haute fréquence, vous voulez des verrous en mémoire.
- Hiérarchies de verrous complexes. Si vous devez verrouiller plusieurs ressources dans un ordre spécifique, SQL devient maladroit. Un vrai lock manager aide.
- Quand vous avez déjà Redis. Si Redis est déjà dans votre stack et que vous êtes à l'aise avec, Redlock est bien. Ne l'évitez pas juste pour éviter des dépendances.
Le takeaway
Pendant des mois, j'ai supposé que la coordination de queue de jobs nécessitait un service de verrouillage dédié. Redis, ZooKeeper, etcd--choisissez votre poison.
Mais ma base de données coordonnait déjà des transactions. Chaque UPDATE est déjà atomique. Chaque clause WHERE est déjà une condition. J'avais juste besoin de les combiner en une seule instruction.
Deux workers font encore la course pour le même job parfois. Mais maintenant un seul gagne. L'autre passe au prochain job. Pas de Redis. Pas d'infrastructure supplémentaire. Juste du SQL faisant ce qu'il a toujours fait.
