La facture montrait 847 heures GPU pour le mois. J'avais traité peut-être 200 heures de vrai travail. Le reste ? Temps d'inactivité. Des GPUs là, faisant tourner des électrons, attendant des jobs qui n'arrivaient pas.
Voilà ce qui s'est passé : mon autoscaler était configuré sur "minimum 1 instance." Ça faisait sens à l'époque--je voulais une faible latence. Quand un nouveau job arrivait, je ne voulais pas attendre le cold start. Donc je gardais un GPU chaud en permanence.
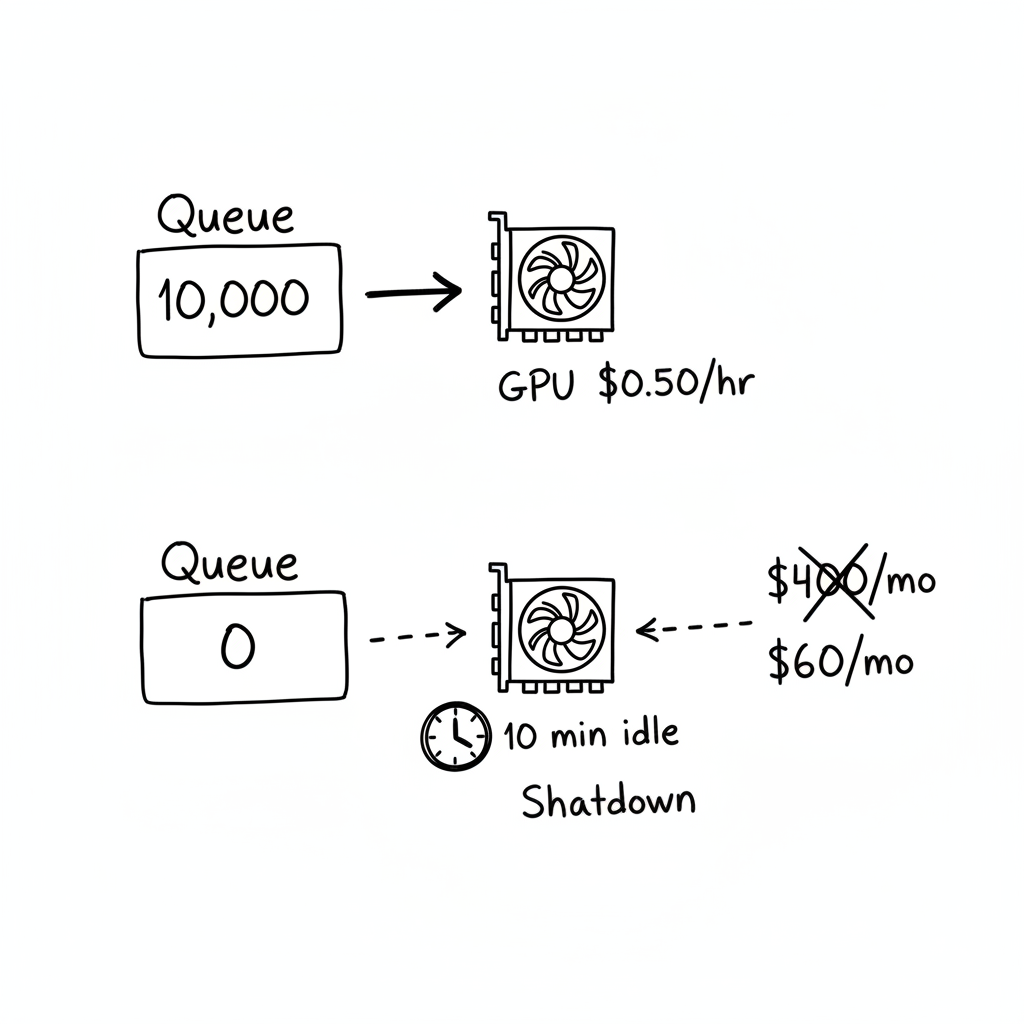
À $0.50/heure, ça fait $360/mois. Pour une instance qui traitait activement peut-être 6 heures par jour. Les autres 18 heures ? Une assurance coûteuse contre une latence qui importait rarement.
L'approche naïve
Mon premier autoscaler regardait l'utilisation CPU. Si l'usage CPU dépassait 80%, scale up. Sous 20%, scale down. Ça marche bien pour les web servers. Mais les workloads GPU sont différents.
Le problème : l'utilisation GPU n'est pas comme l'utilisation CPU. Un GPU peut être "idle" (0% d'utilisation) tout en étant essentiel pour le prochain batch. Et les coûts GPU sont 10-50x les coûts CPU. Scaler basé sur l'utilisation ignore ce qui compte vraiment : y a-t-il du travail à faire ?
La réalisation
Je revisais les factures quand j'ai remarqué quelque chose. Mes jours les plus chers n'étaient pas quand je traitais le plus de données. C'étaient les dimanches--quand rien ne se passait mais le GPU tournait toujours.
Le changement mental : l'autoscaling n'est pas à propos de l'utilisation des ressources. C'est à propos de la profondeur de la queue vs. le coût.
Si la queue a 10 000 items, payez pour un GPU. Si la queue a 0 items pendant 10 minutes, arrêtez de payer pour le GPU. L'utilisation n'importe pas. Les dollars par item traité importent.
Le twist : workers auto-terminants
Voilà où ça devient intéressant. Mes GPU workers n'attendent pas juste d'être tués--ils se tuent eux-mêmes.
Les workers pollent la queue avec un timeout. Si aucun job n'arrive, ils trackent le temps d'inactivité. Quand le temps d'inactivité dépasse un seuil (10 minutes), ils loguent "No work for 10 minutes. Shutting down" et exit.
Pourquoi l'auto-termination ? Parce que l'orchestrateur pourrait crasher. Ou perdre la connectivité. Ou avoir un bug. Si le worker attend que l'orchestrateur le tue, il pourrait attendre pour toujours--accumulant des coûts tout le temps.
Les workers auto-terminants sont un filet de sécurité. Même si tout le reste échoue, le worker finira par remarquer qu'il ne fait rien et s'éteindra.
"L'autoscaling GPU ne devrait pas être à propos de l'utilisation--il devrait être à propos de la profondeur de la queue et du coût par item."
La couche d'optimisation des coûts
Tous les GPUs ne sont pas égaux. Un RTX 3090 coûte $0.25/heure sur les marchés spot. Un A100 coûte $1.50/heure. Pour mon workload, le 3090 était assez rapide.
J'ai ajouté une sélection d'instance consciente du coût. L'autoscaler cherche les GPUs disponibles avec un seuil de prix maximum et un score de fiabilité minimum. Il choisit l'option la moins chère. Si rien de pas cher n'est disponible, il se rabat sur des instances plus chères mais fiables.
L'autoscaler considère le coût comme une contrainte primaire, pas une réflexion après coup. Je préférerais attendre 5 minutes pour un GPU pas cher que payer 6x pour une disponibilité immédiate.
Ce que j'ai mal fait initialement
Je ne gérais pas les interruptions d'instances spot. Les GPUs pas chers se font récupérer sans avertissement. La première fois que c'est arrivé, j'ai perdu 2 heures de travail. Maintenant les workers checkpointent leur progrès tous les N items. Quand un nouveau worker démarre, il reprend du dernier checkpoint.
Mon timeout d'inactivité était trop agressif. J'ai commencé avec 2 minutes. Mais ma soumission de jobs était bursty--un batch se complétait, puis 3-4 minutes de rien, puis un autre batch. Les workers mouraient et respawnaient. Je gaspillais plus sur les cold starts que j'économisais sur le temps d'inactivité. J'ai analysé mes patterns de jobs et trouvé le bon timeout : 10 minutes couvre 95% des gaps inter-batch.
J'ai oublié le coût de l'orchestrateur. L'autoscaler lui-même tourne 24/7, pollant les queues, checkant les instances. Sur une VM à $5/mois, c'est négligeable. Mais je le faisais initialement tourner sur une instance à $50/mois "pour la fiabilité." L'autoscaler coûtait plus que les GPUs certains mois.
Je ne trackais pas le coût par item. Sans métriques, je ne pouvais pas dire si mes optimisations marchaient. Maintenant je logue items traités, coût GPU, et coût par item. Ça me permet de voir les tendances. Quand le coût par item spike, quelque chose cloche--peut-être la queue est trop sparse, ou le GPU est overkill pour le workload actuel.
La checklist
Si vous implémentez ça :
- Scaler basé sur la profondeur de la queue, pas l'utilisation des ressources
- Ajouter un délai avant de scale down (éviter le thrashing)
- Implémenter des workers auto-terminants comme filet de sécurité
- Faire que les workers checkpointent le progrès pour les interruptions d'instances spot
- Ajouter des contraintes de coût à la sélection d'instance
- Tracker les métriques de coût par item
- Alerter quand les instances tournent idle plus longtemps que prévu
- Considérer des types d'instance de fallback quand les pas chers sont indisponibles
Le takeaway
Pendant des mois, je pensais que l'autoscaling était à propos de l'utilisation. Garder les ressources occupées. Scale up quand elles sont surchargées. Scale down quand elles sont sous-utilisées.
Mais les coûts GPU ont changé l'équation. Un GPU utilisé à 90% coûte pareil qu'un GPU utilisé à 10%. Ce qui compte c'est s'il y a du travail dans la queue--et si vous payez pour l'option la moins chère qui peut le gérer.
Maintenant mes GPUs se lancent quand le travail arrive et meurent quand le travail est fait. La facture est passée de $400/mois à $60/mois. Le travail se fait tout aussi vite. J'ai juste arrêté de payer pour des queues vides.
