The enrichment service was down for 20 minutes. Not a big deal--services go down. But when it came back up, I had 50,000 items stuck in a queue, and our search index hadn't updated in half an hour.
Users were searching for products we'd added that morning. Nothing showed up. The products existed in our system, but they were waiting in line behind a backlog of items that needed "enrichment" before they could be indexed.
That's when I realized I'd built a pipeline with a single chokepoint. And every time the slow part got slower, the fast part stopped entirely.
How I Got Into This Mess
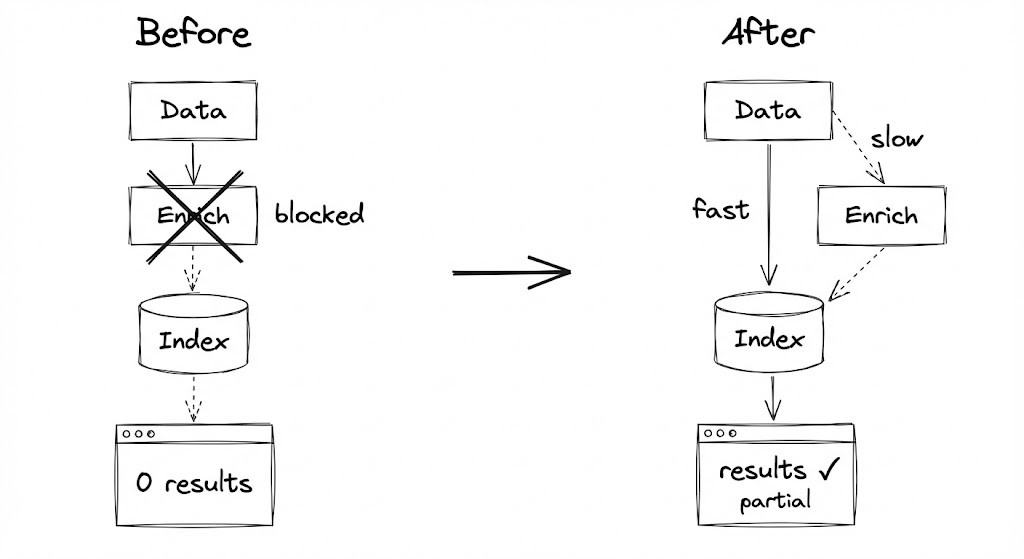
The original architecture was simple and sensible. When a new product arrived:
- Fetch the basic data (name, price, image URL)
- Call the enrichment service (get descriptions, extract keywords, run classification)
- Index the complete record
One pipeline. One flow. Easy to reason about.
The problem was step 2. The enrichment service called external APIs. Sometimes those APIs were slow. Sometimes they rate-limited us. Sometimes they just... didn't respond.
When step 2 took 500ms instead of 50ms, no big deal. When it took 5 seconds, we started falling behind. When the service went down entirely, everything stopped.
I tried the obvious fixes. Retry logic. Timeouts. Parallelization. They helped at the margins, but they didn't solve the fundamental problem: I was blocking fast operations on slow ones.
The Question That Changed Everything
I was explaining the problem to a colleague, and she asked: "Why do you need enrichment before indexing? Can't users search for the product by name while you're still fetching the description?"
I started to explain why that wouldn't work... and then stopped. Because actually, it would work. Most of our searches matched on product name and brand. The enrichment data made results better, but its absence didn't make them impossible.
The mental shift: I was treating "complete" as a prerequisite for "findable." But findable-with-gaps is better than not-findable-at-all.
Two Pipelines, Not One
Here's what I built instead:
PHASE 1: INITIALIZE (Fast Path)
+---------------------------------------------------------+
| Data arrives -> Basic validation -> Index immediately |
| |
| Latency: < 1 second |
| Completeness: ~50% of fields |
| Priority: MAKE IT FINDABLE NOW |
+---------------------------------------------------------+
|
v
[Enrichment Queue]
|
v
PHASE 2: ENRICH (Slow Path)
+---------------------------------------------------------+
| Dequeue -> Fetch details -> Merge with existing -> Update|
| |
| Latency: minutes (acceptable) |
| Completeness: 100% of fields |
| Priority: MAKE IT COMPLETE EVENTUALLY |
+---------------------------------------------------------+
The key insight: Phase 1 never waits for Phase 2. They're completely decoupled. If the enrichment service goes down, items still get indexed. They're just... incomplete. For now.
"Incomplete data that's searchable is better than complete data that's invisible."
The Part That Was Trickier Than Expected
The merge logic. When enrichment data arrives, you can't just overwrite the existing record. Why not?
Because while the item was waiting in the enrichment queue, the fast path might have updated it. Maybe the price changed. Maybe availability changed. If you blindly overwrite with the enrichment data, you might clobber fresher information.
I ended up defining explicit rules for each field type. The merge function checks each field's type and applies the right rule. It's more code than I wanted, but it's explicit about what wins when.
What Bit Me in Production
Users noticed incomplete records. They'd search, find something, click through, and see a blank description. Some complained. I added a visual indicator--a subtle "loading more details..." message--and the complaints stopped. Being honest about incompleteness was better than pretending it didn't exist.
The enrichment queue grew unbounded. During a particularly bad outage, I came back to 200,000 items waiting for enrichment. The queue was eating memory. I added backpressure: if the queue exceeds a threshold, pause ingestion or drop low-priority items. It felt wrong to drop work, but it was better than crashing.
Priority matters. Not all enrichments are equal. A product someone just searched for should jump ahead of a product added six months ago. I added priority levels with conditions for critical, high, normal, and low priority items.
Staleness creeps in. Enrichment data can get stale too. That description from six months ago might reference a feature the product no longer has. I added a background job that periodically re-queues old items at LOW priority for refresh.
When NOT to Use This
This pattern adds complexity. Skip it when:
- Completeness is required. If downstream systems break on incomplete data, you can't serve partial records.
- The slow path is actually fast. If enrichment reliably takes less than 100ms, just do it inline.
- Data arrives complete. If your upstream provides full records, don't artificially split them.
- Volume is low. If you're processing 100 items a day, users can wait for complete data.
The Takeaway
For months, I thought of my pipeline as one thing with two speeds. The fast part and the slow part. But they weren't two speeds of one thing--they were two separate systems that happened to process the same data.
Once I separated them, the fast path got faster (no blocking on slow operations), and the slow path got more reliable (it could retry and recover without affecting the index). The index was sometimes incomplete, but it was never stale.
Findable-but-incomplete beats complete-but-invisible. Every time.
