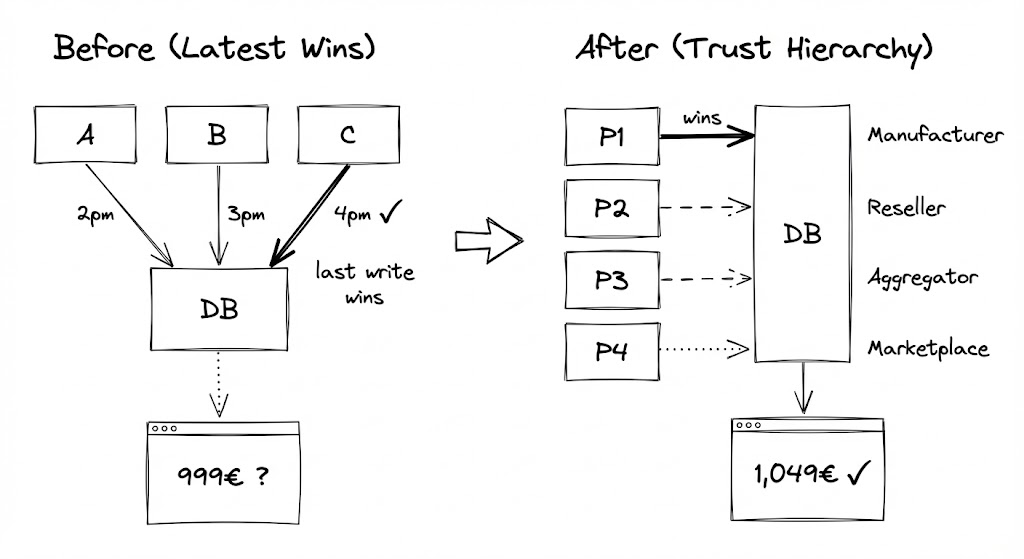
You scrape three vendor sites. All three list the same laptop. Vendor A says it's 999 euros. Vendor B says 1,049 euros. Vendor C says 999 euros but shows "Out of stock." Which price do you show your users?
This isn't a data quality problem. It's a trust problem. And in production systems that aggregate from multiple sources, conflicting data is the norm, not the exception.
The Problem with "Latest Wins"
The naive approach is to use the most recent value. You scrape Vendor A at 2pm, Vendor B at 3pm, Vendor C at 4pm. Vendor C wins. Your database now says the laptop is out of stock at 999 euros.
But what if Vendor C is wrong? What if they're just slow to update inventory? What if Vendor B, despite being scraped earlier, is actually the manufacturer's official distributor with real-time pricing?
Latest wins fails because it treats all sources as equals. They're not.
Trust Hierarchies
A trust hierarchy is a decision framework for resolving conflicts. You assign each source a priority level based on reliability, freshness, and authority. When data conflicts, the highest-priority source wins--regardless of timestamp.
Here's how it worked at Flip:
- Priority 1: Manufacturer API (real-time, authoritative)
- Priority 2: Authorized reseller site (official, but may lag)
- Priority 3: Third-party aggregator (reliable, but indirect)
- Priority 4: Marketplace listings (variable quality)
When the manufacturer API said "1,049 euros, in stock," that beat everything--even if a marketplace listing was scraped 2 hours later claiming 999 euros.
"The best data isn't the newest data. It's the data from the source you trust most."
Implementation
The implementation is simpler than you think. Add a source_priority field to your ingestion metadata. When merging updates, check priority first, timestamp second.
def merge_product_data(existing, new_data):
if new_data.source_priority > existing.source_priority:
return new_data
elif new_data.source_priority == existing.source_priority:
return new_data if new_data.timestamp > existing.timestamp else existing
else:
return existing
This preserves recency within a priority tier while respecting source authority across tiers.
When to Override
There are cases where you want to override the hierarchy:
- A lower-priority source reports "discontinued"--that's likely correct
- Multiple low-priority sources agree on a price change--consensus matters
- High-priority source hasn't updated in days--staleness threshold
These edge cases require custom logic. But for 95% of conflicts, trust hierarchy is enough.
Why This Matters
Trust hierarchies aren't just about picking the "right" price. They're about encoding your domain knowledge into your data model. They make your system's decision-making explicit and debuggable.
When a user asks "Why is this price different from what I saw elsewhere?" you can answer: "We prioritize manufacturer data over marketplace listings." That's better than "Our scraper ran at 4pm."
Good data architecture isn't about preventing conflicts. It's about resolving them correctly.
