The new embedding model was 15% better on our benchmarks. Time to re-embed everything.
I wrote the migration script: select all items, generate new embeddings, update the index. Simple enough. I started it, went to lunch, came back to check progress.
That's when I saw it. Half the items were being skipped with the message: "Embedding unchanged--exact same vector."
Strange. The new model should produce different vectors. I dug in. Turns out, I'd already run the new model on half the catalog during testing last week. Those items had v2 embeddings. But my migration script didn't know that. It re-embedded everything, noticed the vectors matched, and skipped the update. But it still computed the embedding first--burning GPU cycles to produce identical results.
I'd just wasted 90 minutes processing items that were already current.
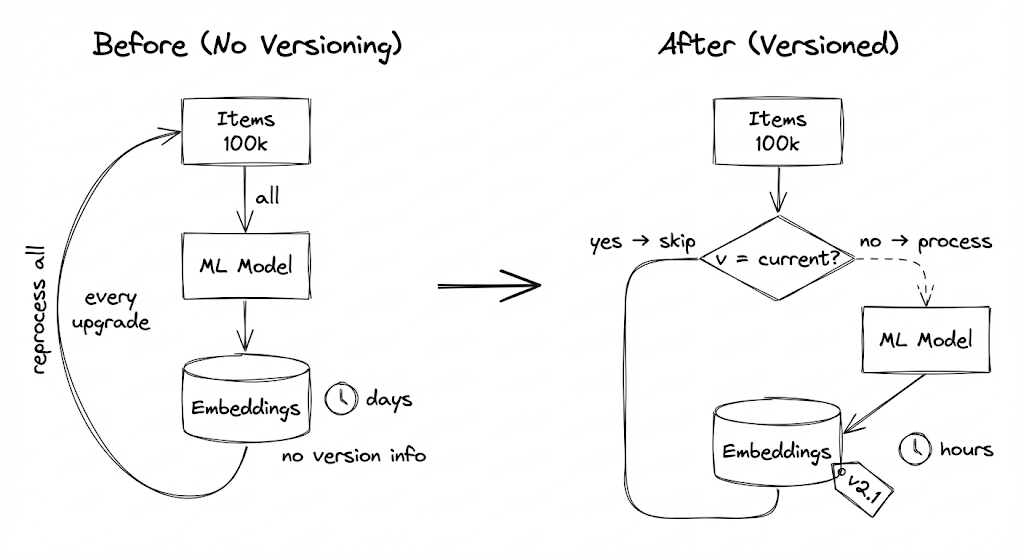
The Naive Approach
My original pipeline didn't track model versions. It just stored embeddings. To check if an item needed re-processing, I'd have to regenerate the embedding and compare. Which defeats the purpose.
So I did what most people do: just re-embed everything when the model changes. Every model upgrade meant a full reprocessing run. Hundreds of thousands of items x 10 seconds each = days of GPU time per migration.
We only upgraded models when absolutely necessary. The pain of re-embedding meant we were stuck on old models longer than we should have been.
The Realization
I was explaining the problem to a colleague, and they asked: "Why don't you just check the version before processing?"
I started to explain why that was complicated... and then stopped. It wasn't complicated. I just hadn't done it.
The mental shift: ML outputs should be versioned like any other artifact. You wouldn't redeploy unchanged code. Why regenerate unchanged embeddings?
I added model version tracking. Now before processing, I check: if the item has no embedding, process it. If the embedding version doesn't match the current version, process it. Otherwise, skip it.
Model upgrade becomes: process items where embedding_version != CURRENT_VERSION. Already-processed items are skipped without computation.
"ML outputs are artifacts, not ephemeral computation. Version them like code."
What I Got Wrong Initially
I only tracked the model name. When I patched a bug in the preprocessing step (v1.0 to v1.1), embeddings with the old preprocessing needed regeneration. But my check only looked at model name. I had to add a full version string.
I forgot about failed processing. Some items failed during embedding--bad images, timeouts. I was storing null embeddings with version "2.0.0". My check said "already current" and skipped them forever. Now I track processing status separately with three states: success, failed, and pending.
Items with status = "failed" can be retried. Items with status = "success" AND version = CURRENT_VERSION are skipped.
I didn't account for dependencies. My embedding depends on the image. If the image changes, the embedding is stale--even if the model version matches. I added a hash of the input. If the image URL changes, the hash changes, and we re-embed even if the model is the same.
I made versions too granular. At first, I bumped the version for every tiny change. Soon I had v1.0.0, v1.0.1, v1.0.2... v1.0.47. Only some changes actually affected output. I started distinguishing between "compatible" and "breaking" changes. Now I only bump when outputs actually differ.
The Bonus: Rollback Becomes Possible
Before versioning, rolling back a model was terrifying. I'd have to re-embed everything with the old model. If the old model was worse for some items but better for others, I had no way to know which.
Now I can see exactly which items were processed by which version. I can re-run specific batches. I can A/B test models on subsets. I can even keep multiple versions in the index and route queries to different ones.
Versioning turned "irreversible migration" into "reversible experiment."
The Checklist
If you implement this:
- Store model name and version with every output
- Track processing status (success/failed/pending) separately from output
- Hash inputs to detect when source data changes
- Define what constitutes a "breaking" version change
- Write queries to find items needing reprocessing
- Consider keeping previous versions for rollback
- Add metrics: what percentage is current? How many pending?
- Set up alerts for failed processing spikes
The Takeaway
For too long, I treated ML model outputs like ephemeral computation. Need embeddings? Run the model. Need new embeddings? Run the model again on everything.
But embeddings are artifacts. They were produced by a specific model version, from a specific input, at a specific time. Tracking that provenance means you can skip redundant work, retry failures, and roll back bad changes.
Now when I upgrade models, I only process what's actually outdated. A large-scale migration that used to take days now takes hours--because most items were already current from testing.
Version your ML outputs. You'll thank yourself during the next model upgrade.
