The retry queue had 50,000 items in it. All failing. All retrying. All failing again.
I dug into the logs. The same error, over and over: "Failed to parse product data." The page structure had changed. My parser was looking for a div that no longer existed.
Here's the thing: those 50,000 retries were never going to work. The website had changed. Retrying wouldn't fix it. But my retry logic didn't know that. It just saw "error" and thought "try again."
Meanwhile, legitimate network timeouts--errors that would succeed on retry--were stuck behind 50,000 doomed attempts.
The Naive Approach
My first retry logic was simple: every error got the same treatment--wait 30 seconds, try again, up to 5 times.
This works fine when most errors are transient. Network blip? Retry. Server overloaded? Retry. Usually succeeds on the second or third try.
But not all errors are transient.
The Realization
I was debugging the parsing failures when I noticed something in my logs. There were actually four distinct error types mixed together:
- Network timeouts - The server didn't respond in time
- Rate limits (429) - We're hitting the API too fast
- Blocks (403) - Our IP got flagged
- Parsing errors - The page structure changed
Each type has completely different retry characteristics. Treating them all the same was the mistake. A parsing error retried 5 times wastes resources on something that will never succeed. A rate limit retried after 5 seconds just gets rate limited again.
The Pattern: Error Categories with Tailored Strategies
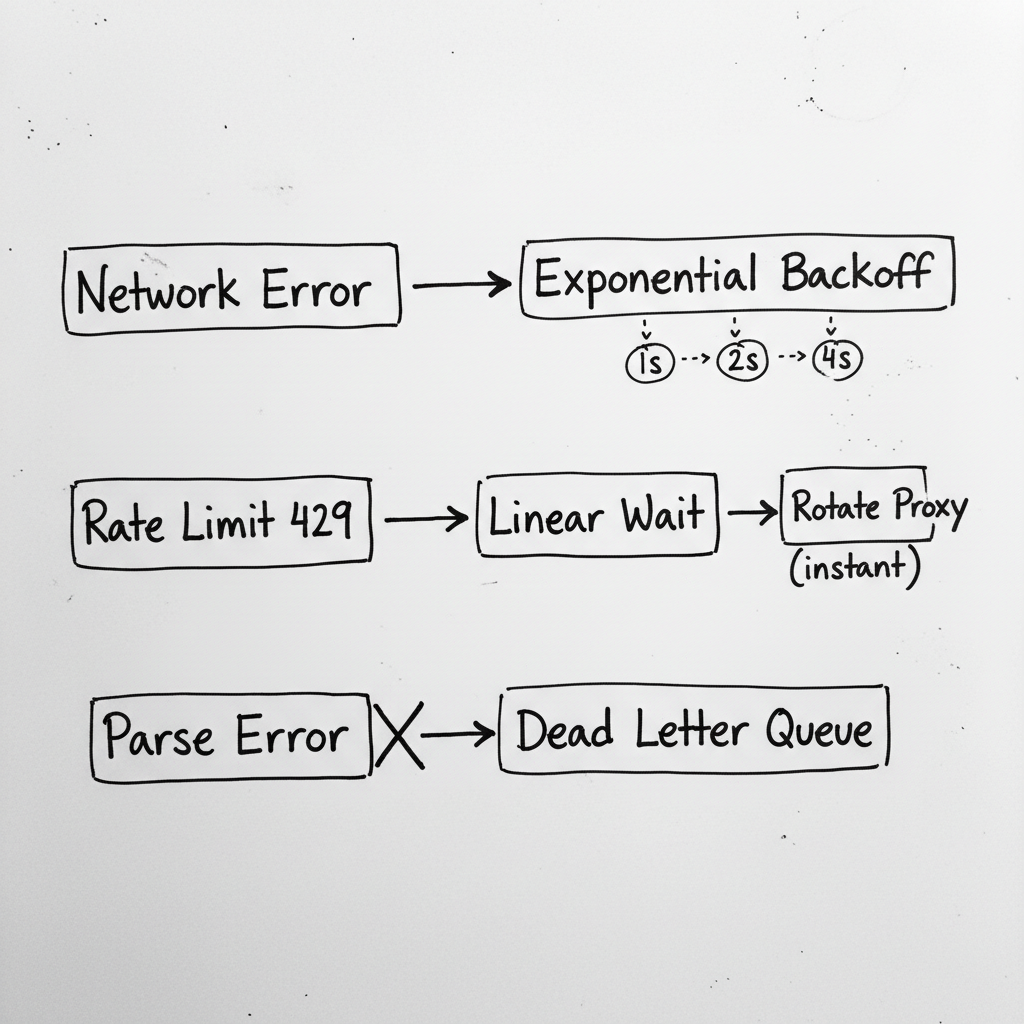
I created an error categorization system with strategies per category. Network errors get exponential backoff and proxy rotation. Rate limits get linear backoff and respect Retry-After headers. Blocks get immediate proxy rotation and alerts. Parsing errors don't retry at all--they go straight to the dead letter queue.
"Not all errors are equal. Don't treat them like they are."
What I Got Wrong Initially
I forgot about cascading failures. When the upstream server went down, I suddenly got thousands of network errors. My alert system sent 500 emails in 10 minutes. I added rate limiting to alerts: one alert per category per hour.
I didn't distinguish between "retry later" and "don't retry." Some parsing errors are actually fixable on retry--if the page was partially loaded. But structural changes are permanent. I added sub-categories for transient vs structural parsing errors.
I hard-coded the strategies. When rate limits changed, I had to redeploy to fix the delay. Now the strategies are configurable via environment variables.
I ignored the Retry-After header. Rate limit responses often tell you exactly how long to wait. I was ignoring this and using my own delay. Now I respect the header when present.
The Checklist
If you implement this:
- Define clear error categories (network, rate limit, auth, parsing, etc.)
- Set per-category retry limits (some should be 0)
- Choose appropriate backoff strategies (exponential for network, linear for rate limits)
- Add rotation/mitigation actions per category (proxy rotation, credential refresh)
- Set alert thresholds per category (immediate for blocks, never for expected rate limits)
- Rate-limit your alerts to avoid cascading spam
- Respect Retry-After headers when present
- Track category-level metrics (what percentage of errors are parsing vs network?)
The Takeaway
For months, my retry logic treated every error like it might be transient. Network timeouts, rate limits, parsing failures--all got 5 retries with 30 second delays.
The result was waste. Parsing errors retried until they died. Rate limits retried too fast. Network errors that would have succeeded quickly got stuck behind thousands of hopeless attempts.
Now errors get categorized first, then handled according to their nature. Parsing errors go straight to the dead letter queue. Rate limits wait the right amount of time. Network errors rotate proxies. The queue drains faster. The alerts are meaningful.
