The invoice showed 847 GPU hours for the month. I'd processed maybe 200 hours worth of actual work.
The rest? Idle time. GPUs sitting there, spinning up electrons, waiting for jobs that weren't coming.
Here's what happened: my autoscaler was set to "minimum 1 instance." Made sense at the time—I wanted low latency. When a new job arrived, I didn't want to wait for cold start. So I kept one GPU warm at all times.
At $0.50/hour, that's $360/month. For an instance that was actively processing maybe 6 hours a day. The other 18 hours? Expensive insurance against latency that rarely mattered.
The Naive Approach
My first autoscaler looked at CPU utilization:
check_scaling():
if cpu_usage > 80%:
scale_up()
if cpu_usage < 20%:
scale_down()
This works fine for web servers. Request comes in, CPU spikes, more instances help. But GPU workloads are different.
The problem: GPU utilization isn't like CPU utilization. A GPU can be "idle" (0% utilization) while still being essential for the next batch. And GPU costs are 10-50x CPU costs. Scaling based on utilization ignores the thing that actually matters: is there work to do?
The Realization
I was reviewing the invoices when I noticed something. My most expensive days weren't when I processed the most data. They were Sundays—when nothing was happening but the GPU was still running.
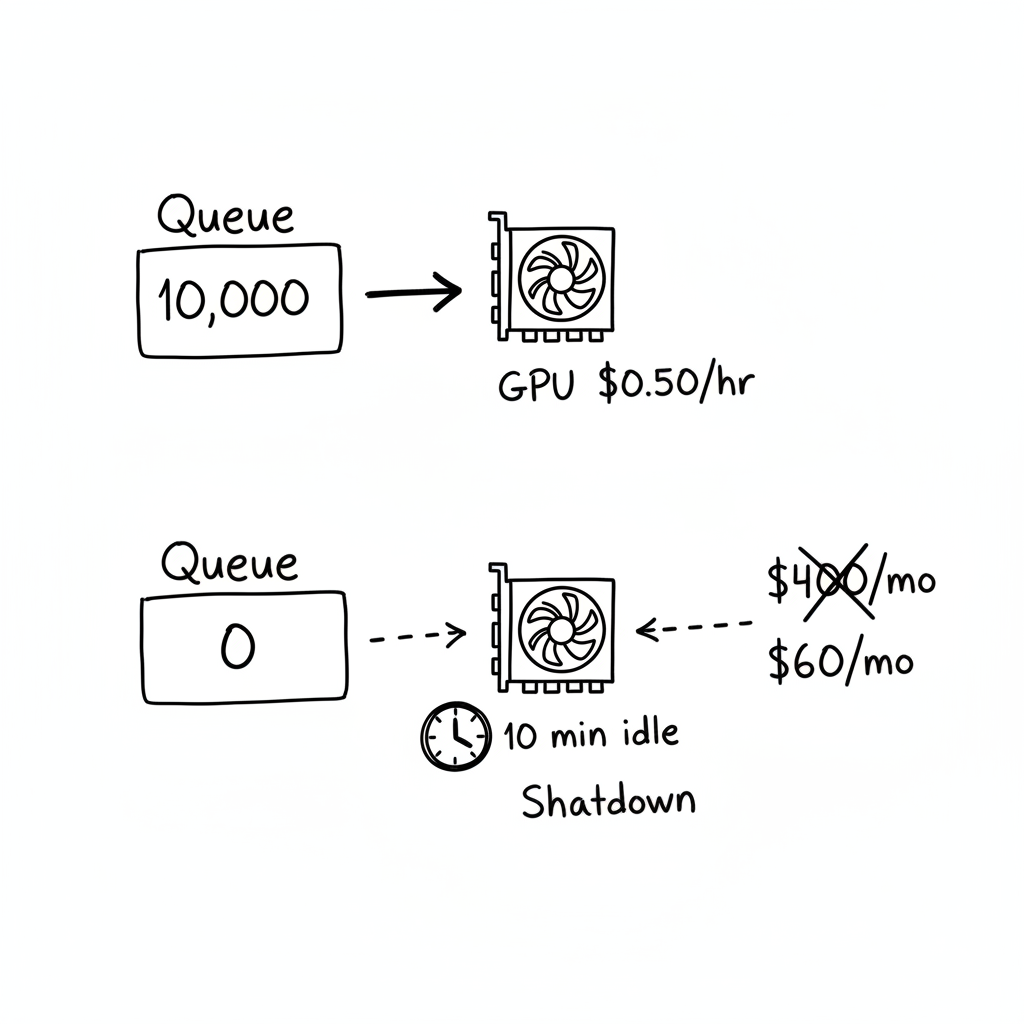
The mental shift: autoscaling isn't about resource utilization. It's about work queue depth vs. cost.
If the queue has 10,000 items, pay for a GPU. If the queue has 0 items for 10 minutes, stop paying for the GPU. Utilization doesn't matter. Dollars per item processed matters.
I rewrote the autoscaler:
check_scaling():
queue_depth = get_queue_depth()
if queue_depth > SCALE_UP_THRESHOLD and active_instances < MAX_INSTANCES:
spawn_worker()
if queue_depth == 0 and idle_time > SCALE_DOWN_DELAY:
terminate_worker()
The SCALE_DOWN_DELAY is crucial. You don't want to kill the instance the moment the queue empties—it might fill up again in 30 seconds. I use 10 minutes. If the queue stays empty for 10 minutes, the worker dies.
The Twist: Self-Terminating Workers
Here's where it gets interesting. My GPU workers don't just wait to be killed—they kill themselves.
# Inside the worker process
last_job_time = now()
while True:
job = poll_queue(timeout=60)
if job:
process(job)
last_job_time = now()
else:
idle_minutes = (now() - last_job_time) / 60
if idle_minutes > MAX_IDLE_MINUTES:
log("No work for {idle_minutes} minutes. Shutting down.")
exit(0)
Why self-termination? Because the orchestrator might crash. Or lose connectivity. Or have a bug. If the worker waits for the orchestrator to kill it, it might wait forever—racking up costs the whole time.
Self-terminating workers are a safety net. Even if everything else fails, the worker will eventually notice it's not doing anything and shut down.
The Cost-Optimization Layer
Not all GPUs are equal. An RTX 3090 costs $0.22/hour on spot markets. An A100 costs $0.30-0.40/hour (prices have dropped significantly since 2024). For my workload that needs VRAM, the A100 is often better value despite higher hourly rate.
I added cost-aware instance selection:
find_gpu():
offers = search_available_gpus(
min_vram_gb=20,
max_price=0.40,
min_reliability=0.9
)
# Score by value, not just price
# See "GPU Spot Market Arbitrage" for the full scoring model
return max(offers, key=score_offer)
The autoscaler considers cost as a primary constraint, not an afterthought. But "cost" means cost-per-item, not hourly rate. A faster GPU at higher hourly rate often costs less per item processed.
What I Got Wrong Initially
I didn't handle spot instance interruptions. Cheap GPUs get reclaimed without warning. The first time it happened, I lost 2 hours of work. Now workers checkpoint their progress every N items. When a new worker starts, it resumes from the last checkpoint.
My idle timeout was too aggressive. I started with 2 minutes. But my job submission was bursty—a batch would complete, then 3-4 minutes of nothing, then another batch. Workers kept dying and respawning. I wasted more on cold starts than I saved on idle time.
I analyzed my job patterns and found the right timeout: 10 minutes covers 95% of inter-batch gaps.
I forgot about the orchestrator's cost. The autoscaler itself runs 24/7, polling queues, checking instances. On a $5/month VM, that's negligible. But I initially ran it on a $50/month instance "for reliability." The autoscaler cost more than the GPUs some months.
I didn't track cost per item. Without metrics, I couldn't tell if my optimizations were working. Now I log:
metrics.record(
items_processed=batch_size,
gpu_cost=instance_hourly_rate * processing_time_hours,
cost_per_item=gpu_cost / batch_size
)
This lets me see trends. When cost per item spikes, something's wrong—maybe the queue is too sparse, or the GPU is overkill for the current workload.
The Pattern
AUTOSCALER_LOOP():
while True:
queue_depth = get_queue_depth()
active_workers = get_active_workers()
# Scale up: queue is backing up
if queue_depth > SCALE_UP_THRESHOLD:
if active_workers < MAX_WORKERS:
spawn_cheapest_available_worker()
# Scale down: queue is empty for a while
if queue_depth == 0:
if empty_duration > SCALE_DOWN_DELAY:
for worker in active_workers:
if worker.idle_time > IDLE_THRESHOLD:
terminate(worker)
sleep(POLL_INTERVAL)
WORKER_LOOP():
last_job_time = now()
while True:
job = poll_queue()
if job:
process(job)
last_job_time = now()
checkpoint_progress()
else:
if (now() - last_job_time) > SELF_TERMINATE_THRESHOLD:
exit(0)
The dual-layer termination (orchestrator + self-termination) ensures workers don't run forever even if the orchestrator fails.
The Checklist
If you implement this:
- Scale based on queue depth, not resource utilization
- Add a delay before scaling down (avoid thrashing)
- Implement self-terminating workers as a safety net
- Make workers checkpoint progress for spot instance interruptions
- Add cost constraints to instance selection
- Track cost-per-item metrics
- Alert when instances run idle longer than expected
- Consider fallback instance types when cheap ones are unavailable
- Make thresholds configurable (queue depth, idle timeout, max price)
When NOT to Use This
- Latency-critical workloads. If cold start time is unacceptable, you need warm instances. Pay for the idle time.
- Predictable, constant load. If you always have work, reserved instances are cheaper than spot.
- When simplicity matters more. This adds complexity. If your GPU bill is $50/month, it's not worth optimizing.
- When spot instances are unreliable. Some workloads can't tolerate interruptions. Use on-demand and accept the cost.
The Takeaway
For months, I thought autoscaling was about utilization. Keep resources busy. Scale up when they're overloaded. Scale down when they're underutilized.
But GPU costs changed the equation. A 90% utilized GPU costs the same as a 10% utilized GPU. What matters is whether there's work in the queue—and whether you're paying for the cheapest option that can handle it.
Now my GPUs spin up when work arrives and die when work is done. The invoice dropped from $400/month to $60/month. The work gets done just as fast. I just stopped paying for empty queues.
Where This Applies
- Batch ML inference (embeddings, classification, OCR)
- Video/image transcoding
- Scientific computing with bursts
- Any GPU workload where latency isn't critical
- Spot instance arbitrage for cost-sensitive processing
